


Weekly Backend #7: 39 Resources and Updates
GPT-4o, Google I/O, Fugaku LLM, Prep for Machine Learning Interviews, and more

Welcome to the Weekly Backend! Here's a comprehensive list of the important ML resources and updates of the past week. Feel free to peruse them and read anything that's interesting to you. Leave a comment to let me know what you think. If you missed last week's updates and resources, you can check it out here.
I’m currently figuring out a better way to share these updates and make them quickly readable and understandable. Part of this will be formatting these updates better. I find this dump to make it difficult to pick out things that are important to you. I’d also like some way of saving all the resources I find and make them queryable based on topic. More to come on that.
Number of machine learning updates: 21
Number of machine learning resources: 18
You can get access to the complete list of resources, my feed, and even interesting job opportunities (coming soon!) by supporting Society's Backend for just $1/mo:
You can also get more updates and resources by following me on X and YouTube. Let's get started!
Say hello to GPT-4o, OpenAI's new flagship model
OpenAI introduces GPT-4o, a new model for audio, vision, and text tasks. Users can now input text and images in the API and ChatGPT. Voice and video input will be added soon. The new model aims to reason in real-time across multiple formats.

An excellent play-by-play thread with information about Google I/O
An X thread highlighting Santiago's takeaways from Google I/O. He was there in person, demoed products, and created a comprehensive list.

Release of “Fugaku-LLM” – a large language model trained on the supercomputer “Fugaku”
A team in Japan released Fugaku-LLM, a large language model with enhanced Japanese capabilities trained on the supercomputer Fugaku. The model has 13 billion parameters and is available for research and commercial use. By utilizing distributed training methods and Japanese CPUs, the team improved computational performance and developed a high-performance and transparent model. The release aims to advance AI research and business applications, offering potential for innovative uses.
Machine Learning Interview Prep
This text is about a study plan for machine learning interviews, including resources, study guides, and testimonials from successful candidates. It covers topics like LeetCode questions, programming languages, statistics, big data, ML fundamentals, and system design. The author shares personal experiences, tips, and a recommended course for aspiring ML engineers to prepare effectively for interviews.
Build an LLM from Scratch is Almost Complete
The book "Build an LLM from Scratch" by Sebastian Raschka is almost complete. The final stages include the classification-finetuning and instruction finetuning chapters. The estimated publication date is Summer 2024. Bonus material is available on GitHub for additional content.
Introducing VideoFX, plus new features for ImageFX and MusicFX
Google introduced VideoFX, a tool that turns text into videos, along with updates for ImageFX and MusicFX to enhance creative projects. VideoFX, powered by Google DeepMind's Veo, allows for emotional and cinematic video creation, and ImageFX now offers better image editing and quality. MusicFX has been updated with a DJ Mode for crafting new beats, with all tools supporting creativity in various languages and countries. These innovations aim to bridge the gap between inspiration and creation, with a focus on responsible AI use.

Running instruction tuning experiments with LoRA
The author conducted many experiments using LoRA/QLoRA and shared key findings for better model performance. Practical tips include using a low rank for LoRA, adding LoRA adapters to linear layers, and tuning learning rates carefully. Observing model outputs on various evaluation sets is crucial for understanding performance.
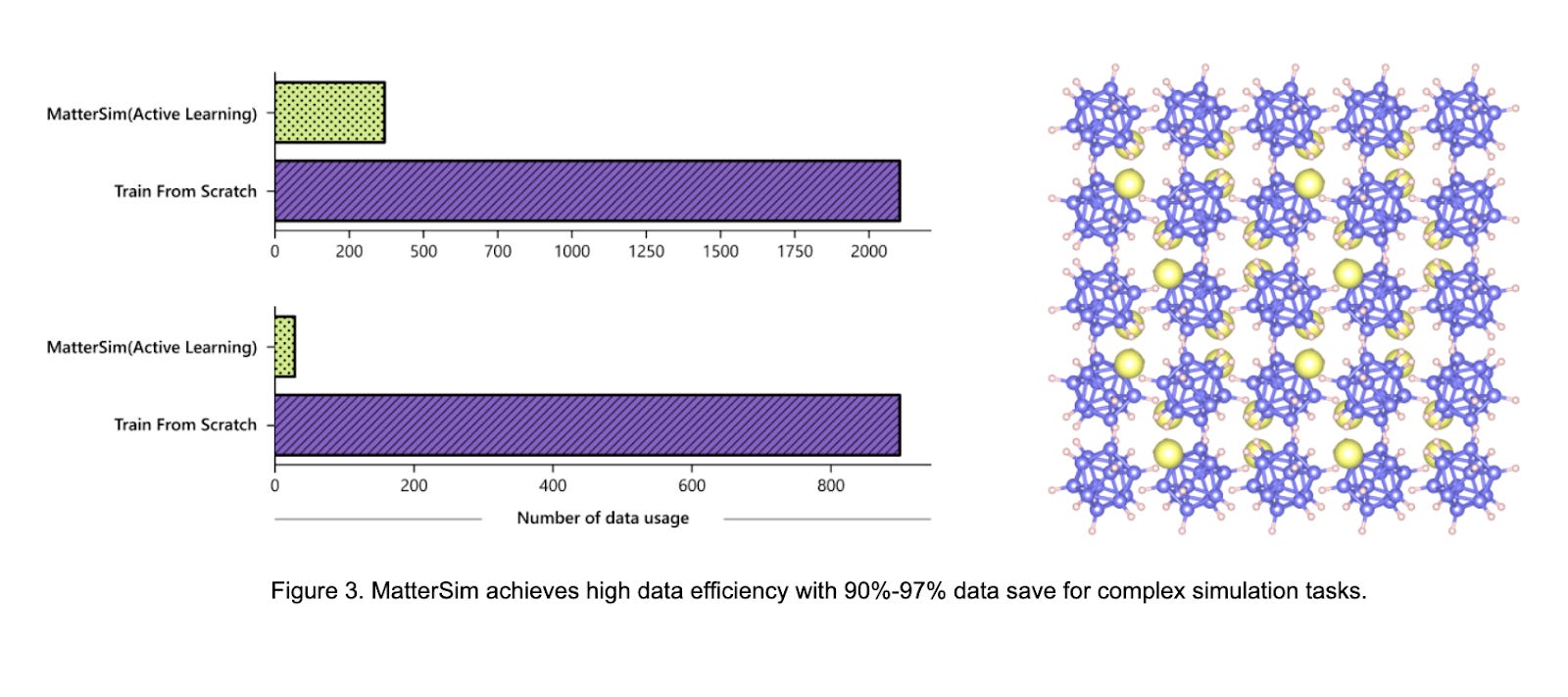
Microsoft Researchers Introduce MatterSim: A Deep-Learning Model for Materials Under Real-World Conditions
Microsoft researchers developed MatterSim, a deep-learning model for accurately predicting material properties. MatterSim uses synthetic datasets and deep learning to simulate a wide range of material characteristics. It offers high accuracy in material property prediction and customization options for specific design needs. By bridging atomistic models with real-world measurements, MatterSim accelerates materials design and discovery.
Machine learning enables cheaper and safer low-power MRI
Machine learning makes low-power MRI more affordable and safer while maintaining accuracy. This advancement could lead to patient-friendly ULF MRI scanners in healthcare settings worldwide. Standard MRI machines are expensive and require specialized infrastructure, limiting accessibility, especially in low-income countries. A new low-power ULF MRI scanner shows promise in producing quality imaging without the need for costly equipment or high power consumption.
It’s only been 2 days since OpenAI revealed GPT-4o
OpenAI recently unveiled GPT-4o, showcasing impressive AI capabilities in just 2 days. Users are discovering groundbreaking applications like video game generation and real-time language translation. GPT-4o is being used for tasks like aiding the visually impaired and assisting with interview preparation. This advanced AI model is revolutionizing how we engage with technology.
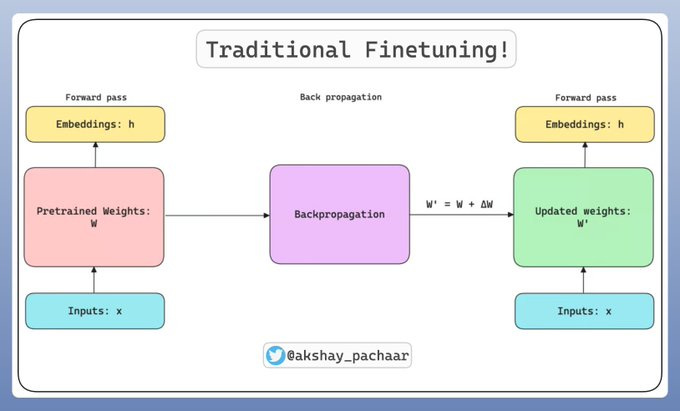
LoRA: Low-Rank Adaptation of LLMs, clearly explained
LoRA is a technique for fine-tuning Large Language Models (LLMs) efficiently. It helps reduce memory usage during adaptation by decomposing the weight matrix into smaller matrices. By using LoRA, fewer parameters need to be fine-tuned, making the process more efficient. Akshay explains LoRA and provides a hands-on coding tutorial to demonstrate its application in fine-tuning LLMs.

Nice implementation of Self Rewarding Language Models
The text discusses a self-rewarding language model implementation by Yuan et al. The model uses LLM-as-a-Judge for self-improvement. It includes automated iteration cycles and configurable parameters for easy adjustments. The implementation focuses on optimizing adaptability and ease of use.
Let's learn how to evaluate a RAG application
The text explains how to evaluate a RAG application using a step-by-step guide. It involves loading a knowledge base and required models, creating a test set generator with customizable options, and loading data into a Pandas DataFrame for analysis. The author also offers a LightningAI Studio with all necessary code for running the evaluation process.
Just a list of some MLX packages to cover your modalities
A list of MLX packages for different modalities was shared by Awni Hannun. Some packages include Chat with MLX, MLX VLM for vision, and lightning-whisper-mlx. Many more MLX projects can be explored by following the provided link.

Tencent’s upgraded LLM for text-to-image generation released on open source platforms
Tencent upgraded its large language model for text-to-image generation by 20% and released the source code on open-source platforms. The new model, Hunyuan, uses the DiT architecture and is designed to understand Chinese commands. This release aims to benefit the industry and promote an open-source ecosystem for vision generation.
Synthetic data generation cannot expand the manifold (a model's knowledge)
Synthetic data generation is helpful but doesn't expand a model's knowledge. It can improve training data quality for curve fitting. Sampling synthetic data from the same distribution may not solve performance plateaus in models.
The best introduction to Statistics and Probabilities I've read
Santiago recommends "The Cartoon Guide to Statistics" as the best introduction to Statistics and Probabilities. The book is easy, fun, and accessible to all backgrounds. Huberman acknowledged a mistake in a clip about statistics, emphasizing the importance of studying the subject. Santiago finds the clip a great advertisement for the need to study statistics.
The Top ML Papers of the Week
Top ML papers of the week include AlphaFold 3 for predicting molecular structures, xLSTM for scaling LSTMs, DeepSeek-V2 for efficient inference, and AlphaMath Almost Zero for enhancing mathematical reasoning. These papers showcase advancements in AI models and techniques for various applications.
AI x Robotics is developing fast
AI x Robotics is rapidly advancing with major updates from various companies this week. Notable developments include new AI models, advanced humanoid capabilities, and innovative tools for drug discovery and video generation. Stay informed on the latest progress by following Brett Adcock for weekly updates. OpenAI, Google DeepMind, Apple, and other key players are shaping the future of AI and robotics.

OpenAI’s Model (behavior) Spec, RLHF transparency, and personalization
OpenAI shared their "Model Spec" to outline their AI models' intended behaviors before fine-tuning, aiming for transparency and better alignment with user needs. This document, praised for detailing reasonable principles and goals, serves as a guide for AI development and helps mitigate risks from user, legal, and regulatory perspectives. OpenAI's approach to model behavior includes promoting helpfulness, fairness, and discouraging harmful content, while also exploring how models can learn directly from these specifications. The discussion around the Model Spec highlights OpenAI's efforts to balance fine-tuning challenges and the potential for personalization in AI use-cases.
Google I/O session on Large Language Models with Keras
Watch the Google I/O session video on Large Language Models with Keras by François Chollet on YouTube. The session covers chat generation, LoRA fine-tuning, model parallel training, style alignment, and model surgery. Enjoy learning about these topics in the video!
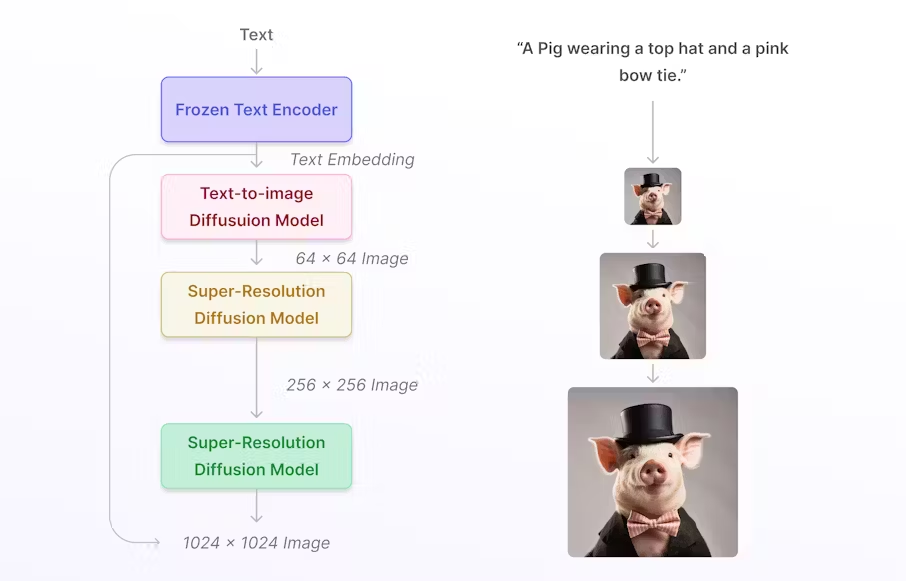
How Diffusion Models are Improving AI [Investigations]
Diffusion models are a type of AI that create high-quality, realistic data by refining random noise through a two-step process. They are versatile, capable of generating images, audio, and more, with the ability to control the outcome closely. Despite their potential, diffusion models require significant computational resources, making them expensive. They stand out for their ability to handle complex data generation tasks better than traditional methods, offering step-by-step control over the final product.
Reliably finding under-trained or 'glitch' tokens
The paper by Sander Land discusses finding under-trained or 'glitch' tokens in language models. They identify numerous tokens in various models and provide examples. Surprisingly, the indicators used can predict both unseen and frequently seen tokens. The study also reveals various issues with tokenizers, often stemming from manual vocabulary additions or misconfigured settings.
Ilya Sutskever is leaving OpenAI
Ilya Sutskever is leaving OpenAI after almost a decade. He believes OpenAI will continue to build safe and beneficial AGI under new leadership. The company's trajectory has been impressive. Sutskever has confidence in the future of OpenAI.
Aligning open language models, a lecture at Stanford
Nathan Lambert gave a lecture at Stanford on aligning open language models. The lecture covered topics like llamas, alpaca, open assistant, qlora, and evaluation. It dives into the history and development of these models.

What is Retrieval Augmented Generation?
Retrieval Augmented Generation (RAG) boosts the knowledge of language models by fetching relevant information from external sources like databases or APIs, ideal for creating specialized Q&A bots. It involves a retrieval component that finds and presents precise context from a knowledge base to the language model, which then uses this context to answer user queries accurately. Various retrieval strategies, including direct query submission and LLM-guided search, enable effective fetching of the most pertinent information. This approach is particularly valuable in domains where standard language models may lack specific knowledge, enhancing their performance significantly.
Keep reading with a 7-day free trial
Subscribe to Society's Backend: Machine Learning for Software Engineers to keep reading this post and get 7 days of free access to the full post archives.