


Weekly Backend #4: 62 Total Resources
Apple’s LLM OpenELM, GPT-4-Turbo, Phi-3, Grok-1.5 Vision, and more

Thank you to all the new subscribers and supporters of Society’s Backend! We are now more than 1000 strong. A huge thanks to you all for reading my writing. I’ll keep sharing the most important things you need to know about machine learning and machine learning engineering.
Welcome to the Weekly Backend! Each week I take you through the important machine learning updates and resources of the past week.
I’m switching up the format a bit. I’m now doing this weekly instead of biweekly. This gives you a lower latency connection to the information and makes it more easily digestible (62 resources instead of greater than 100 each time). I’ve also started pulling information about the sources straight from my notes instead of rewriting it. There may be more typos, but it allows me to add more information with less of a filter. I also use AI to generate a summary of the resources for quick skimming. If you dislike anything about the format, let me know! I’m trying to make it better.
Total number of updates: 31
Total number of resources: 31
You can become a supporter and get access to all resources and my notes for just $1/mo:
Let's get started!

GPT-4 Turbo is now available to paid ChatGPT users
The new GPT-4 Turbo is now accessible for paid ChatGPT users. It offers enhanced writing, math, reasoning, and coding abilities. The update aims to provide more concise and conversational responses.

But what is a GPT? Visual intro to Transformers | Deep learning, chapter 5
Great overview of both deep learning and transformers. This is such a good visual explanation I've even added it as a resource to my Machine Learning Road Map. Note: this does not go over the attention mechanism, that's in a separate video.

Calculus Made Easy
"Calculus Made Easy" is a comprehensive text covering various topics related to calculus, from basic concepts to more advanced techniques like integration and differentiation. The book uses a geometrical approach, offering readers a different perspective compared to traditional symbolic methods.

OpenELM: An Efficient Language Model Family with Open-source Training and Inference Framework
Sebastian Raschka, PhD shared insights on Apple's new "OpenELM" language model, highlighting its architecture and performance compared to OLMo. He appreciated the detailed discussion in the paper but noted the lack of in-depth explanation on certain aspects like subsampling and architecture tweaks. Raschka found the comparison between LoRA and DoRA for parameter-efficient finetuning surprising but commended the researchers and Apple for their work.
LLaMA-3 is a prime example of why training a good LLM is almost entirely about data quality
An excellent overview of the importance of data quality in machine learning as it relates to Llama 3 and a walkthrough of the information released about Llama 3. LLM architecture is pretty standardized and datasets will make the real difference in quality.
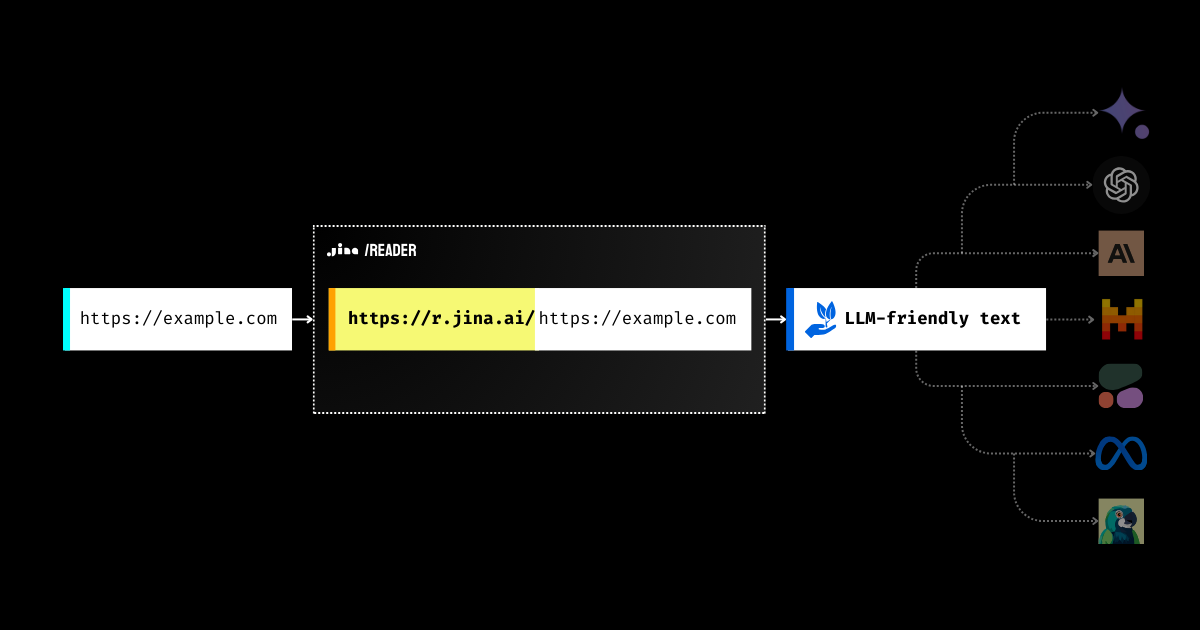
jina-ai/reader
Making information available to LLMs is paramount for making LLMs valuable. This introduces a way to quickly turn the contents of a webpage LLM-friendly. A live demo is included in the source.

Let's compare Llama-3 & Phi-3 using RAG:
The text compares Llama-3 and Phi-3 using RAG for building a chat interface application. It explains key components like loading the knowledge base, creating embeddings, and setting up a query engine. The author shares code and detailed descriptions for each component, inviting readers to explore and try it themselves.
This is an excellent step-by-step guide to testing LLMs by creating RAG systems.

Mark your calendars for #WWDC24, June 10-14
Apple seems to be taking a focus on AI for WWDC this year. If they are, it'll be a huge step forward for getting AI into everyone's hands. Definitely worth a watch.

101 real-world gen AI use cases featured at Google Cloud Next ’24
Google Cloud customers are using generative AI for various applications like customer service, data analysis, and creative ideation. Over 100 industry leaders are showcasing how AI is transforming their operations and improving efficiency. AI technologies like Vertex AI and Gemini models are enabling real-world use cases across different sectors.

Llama 3 models are in the 🤗 MLX Community
Llama-3 is already in MLX! MLX is making machine learning more accessible to individual researchers/ML builders. MLX is also a huge step forward in making AI accessible because it allows training and using models in ways that were previously only available on PC. MLX team has been making many improvements very quickly recently.
JP Morgan presents FlowMind
JP Morgan introduces FlowMind, a system using Large Language Models to automate workflow generation. FlowMind ensures data integrity and confidentiality in financial services by minimizing direct interaction with sensitive information. User-friendly features like high-level descriptions and effective feedback mechanisms make FlowMind successful in automating tasks.
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
The text discusses how current language models can be vulnerable to attacks due to considering all instructions equally important. To address this vulnerability, the author proposes an instruction hierarchy to prioritize instructions. By training models to selectively ignore lower-privileged instructions, the proposed method increases robustness against attacks. Testing on GPT-3.5 shows significant improvements in security without sacrificing performance.

Phi-3 has "only" been trained on 5x fewer tokens than Llama 3
Phi-3 has been trained on fewer tokens than Llama 3 but performs equally well. It has a smaller size and can be deployed on a phone. The key to its success is high-quality, filtered web data and synthetic data.
This is another example showcasing how important data quality is.

LLM-as-a-judge overview
LLM quality has improved significantly in recent years, making reliable evaluation challenging. One popular method is LLM-as-a-judge, utilizing GPT-4 for model assessment. Resources like the referenced paper on LLM-as-a-judge provide valuable insights for practitioners implementing evaluation strategies.
Cameron gives a good overview of LLM-as-a-judge and 3 methods for evaluating LLM output. This is complete with graphics and links to papers with supporting information.

Things Everyone Should Understand About the Stanford AI Index Report
The Stanford AI Index Report tracks AI progress and highlights ethical considerations in various domains, such as technical performance, research trends, and industry adoption. It provides crucial insights for policymakers, business leaders, and the general public to understand the evolving landscape of AI. The report reveals key takeaways, including AI advancements surpassing human performance in certain tasks and the increasing importance of responsible AI development.

Know Your Benchmarks
An explanation of the Chatbot Arena benchmark everyone uses to compare state-of-the-art LLMs written by yours truly.

How to Fine Tune Llama 3 for Better Instruction Following?
A step-by-step video from tutorial Mervin Praison for fine-tuning the brand new Llama 3. Merving is always quick to explain and create tutorials for new AI advancements.

Using AI to build better Developer Tools [Breakdowns]
Devansh discusses using AI to improve Developer Tools, focusing on AI-powered coding assistants and their impact on developer productivity and happiness. Developers want AI tools to support them in tasks without taking over the entire process, providing guidance but still allowing for oversight and control. Implementing AI in workflows requires clear communication, understanding ML model decisions, and robust testing to ensure effectiveness and safety.
This includes information about what developers actually want from AI tools (often overlooked) and AI can give it to them.
Microsoft just revealed an AI that can produce a deepfake from only 1 photo
AI updates on April 18th include: Microsoft releasing a model that can easily make deepfakes, Boston Dynamics introduces a robot designed for real-world applications with incredible flexibility, Tencent releases a model that can create a detailed 3D mesh from a single 2D images, and much more. If you don't follow Rowan on X, I suggest you do.

AI Accelerators: The Cambrian Explosion
The text discusses the rapid growth of new computer architectures for AI accelerators in the coming decade, highlighting key players and advancements in the field. It mentions various accelerator designs developed by companies like Google, Amazon, Microsoft, and others, emphasizing the significant progress and investment in AI hardware over the past decade. The post provides insights into the fabrication, deployment, and software aspects of these AI accelerators, showcasing the diverse range of designs and technologies used in this evolving industry.

Grok-1.5 Vision Preview
xAI is making moves with a vision model. It's always good to have more players in this space and its made especially interesting because of xAI's access to data on X giving them an incredibly large training pool.
The Open Medical-LLM Leaderboard: Benchmarking Large Language Models in Healthcare
It's important to understand benchmarks and that we have benchmarks to measure meaningful performance. This is a leaderboard to benchmark medical-focused LLMs. I have a brother who is a doctor and he said they are absolutely abysmal currently. Hopefully this will shine some light on improving them.
Phi-3 is here
Phi-3 has arrived, bringing exciting updates and improvements. A demonstration video showcases Phi-3-mini's capabilities, with open weights release and more announcements coming soon. The Phi-3 family, developed by a dedicated team, promises impressive performance and updates in the near future.
There is also a short demo video showing what Phi-3-mini can do.

GPT-5: Everything You Need to Know
The article discusses the anticipation and pressure surrounding the upcoming release of GPT-5 by OpenAI in a competitive AI landscape. It explores what to expect from GPT-5, including new features like reasoning and agents, potential business impacts, and the race with rival tech companies. The detailed three-part structure covers meta discussions, known information, and speculative insights about GPT-5's capabilities and implications.
Gemini 1.5 Pro has entered the (LMSys) Arena!

Gemini 1.5 Pro has entered the LMSys Arena, standing out for its strong performance in multimodal tasks and audio processing. The model is now ranked #2 on the leaderboard, showcasing its prowess in handling long prompts. This free API from GoogleDeepMind offers exciting possibilities for developers and the community.

Unit Testing for LLMs: Why Prompt Testing is Crucial for Reliable GenAI Applications[Guests]
This is an excellent overview of why and how LLMs can be tested from Devansh. It also includes an overview of Promptfoo, which is an open-source framework to write and run these tests.
Don’t bet against Meta AI
Meta is making Llama-3 level AI available to many more people via Meta AI. This is a big step toward getting AI into the hands of everyone and it's an even bigger deal because of the quality of that AI.
Elon Musk is reportedly raising $6 billion for xAI
Elon Musk's AI startup, xAI, is close to securing $6 billion in funding, aiming for an $18 billion valuation. SenseTime launched a new AI model, SenseNova 5.0, surpassing GPT-4 Turbo in benchmarks. Adobe introduced VideoGigaGAN for 8x video upscaling, and Apple released OpenELM models for efficient performance on devices. Sanctuary AI unveiled the seventh generation of its Phoenix humanoid robot, hinting at future real-world integration.
Bigger is not Always Better: Scaling Properties of Latent Diffusion Models
The study examines how the size of latent diffusion models affects their sampling efficiency. Smaller models can often generate high-quality results more efficiently than larger ones under the same inference budget. These findings suggest new strategies for scaling latent diffusion models to improve generative capabilities within resource constraints.
Explaining llm.c in layman terms
Andrej Karpathy recently recreated the training code for GPT-2 in C. This is an overview by Andrej Karpathy explaining why LLM.c is important. Training Large Language Models like GPT-2 involves complex code and dependencies, such as PyTorch. Simplifying this process by directly implementing in low-level language (C) can reduce complexity but sacrifices flexibility and speed. Despite challenges, this direct approach is being pursued for its educational and potentially practical benefits.
Keep reading with a 7-day free trial
Subscribe to Society's Backend to keep reading this post and get 7 days of free access to the full post archives.