


Know Your Benchmarks
How the Chatbot Arena leaderboard for LLMs works and why it’s important to understand

Thank you everyone for your patience as I’ve been moving and unable to find the time to write and share resources with you. We’re almost all settled in and I’m back to writing. I’ve added a link to a cheat sheet to the CS 229 portion of the Machine Learning Road Map and I’ve updated the resources on my website to include my list of machine learning-related people to follow on X. As a thank you to supporters, the first paid-only article will be coming later this week.
Also, welcome to everyone who recently joined Society’s Backend. It’s great to have you! Make sure to email me to introduce yourself if you haven’t already.
Do you remember that moment when you were a kid and you realized that your parents weren’t always correct about everything? That was a big moment for me. I realized many more things were subjective than I thought. I’ve carried this mindset into many situations in life and machine learning is no different.
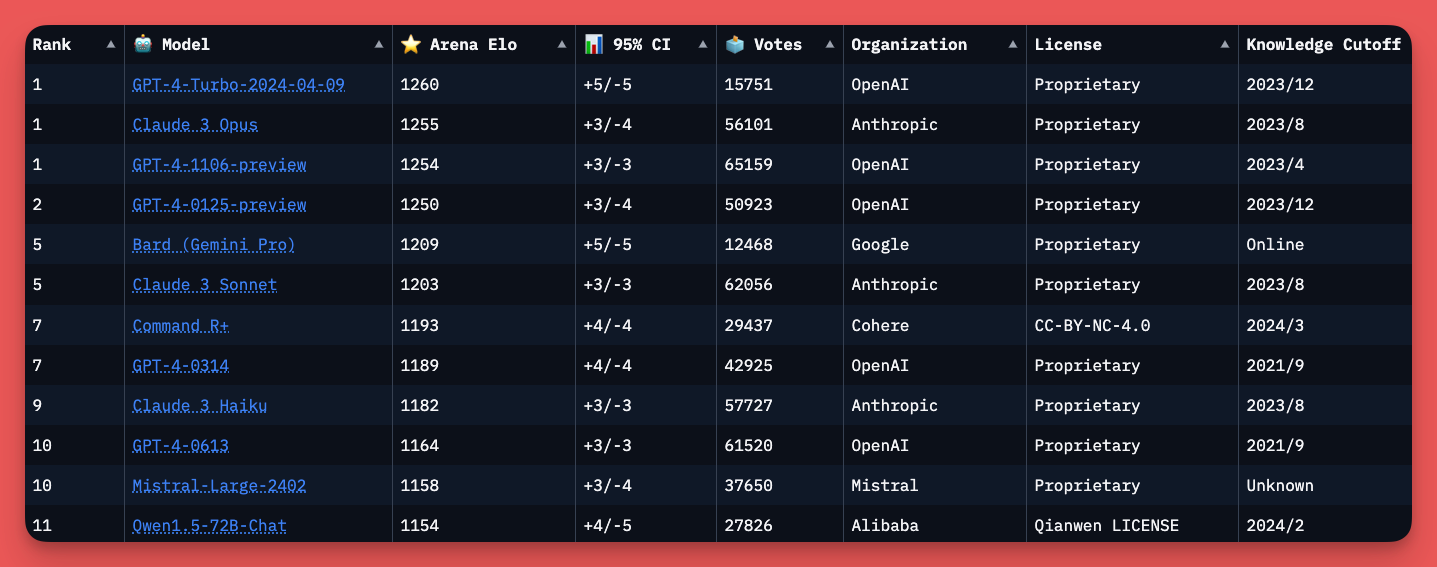
With the release of GPT-4-Turbo I see a lot of posts with pictures like the picture I’ve included above showing GPT-4-Turbo ahead of its competitors. The screenshot above is from the LMSYS Chatbot leaderboard for LLMs, which has become a standard for comparing performance across LLMs. Seemingly every month (at least) we have a new LLM topping this leaderboard. Sometimes it shows a significant improvement in LLM performance, but other times it doesn’t mean much.
This leaderboard is often used as a source to make claims on social media purely to generate engagement. Claims are made of a huge, new state-of-the-art LLM with a screenshot of this chart showing the new LLM at the top when in reality there haven’t been any significant changes in LLM performance at all. These posts work well for engagement because most people on social media won’t read the chart and almost all won’t learn to understand the leaderboard themselves. Members of Society’s Backend won’t be these people.
In general, it’s important to understand how benchmarks are designed. This is especially true in machine learning where state-of-the-art is moving very quickly, being applied widely, and the field is introducing new technologies that don’t have standard evaluation practices. Understanding how a benchmark works helps you know what it tells you and helps you better use the benchmark to draw conclusions. Benchmarking is an area where results are often misconstrued because benchmarks can be used to justify outcomes they aren’t fit to measure. Benchmarks are useful tools, but not if they aren’t understood.
To make it clear: the Chatbot Arena is an excellent benchmark. It’s supported by groups such as Kaggle, a16z, and Huggingface (and more) and was created by the LMSYS Org. Let’s run through what it is and why understanding it is important.
What the Chatbot Arena leaderboard is
The Chatbot Arena leaderboard uses an Elo rating system to rank LLM chatbots against one another. This is a ranking system that pits two different players against one another and increases or decreases each player’s score based on the expected versus actual outcome of the match. Losing decreases a player’s score while winning increases it. The amount a score changes is based on the difference between a player’s own Elo rating and the rating of their opponent. As many matches are scored, a ranking of all players is created based on all match outcomes. This is commonly used in sports, esports, and board games (most notably chess). For Chatbot Arena, the LLMs are the players.
The leaderboard works by crowdsourcing LLM competitions. Users can visit the leaderboard website and give two different anonymized LLMs a prompt. The user provides feedback for which they think provided better output. You can help with the crowdsourcing effort by visiting the Chatbot Arena website and clicking the “Arena (battle)” tab to battle LLMs yourself. A great deal of effort is put into ensuring the crowdsourced prompts are sufficiently diverse and the human ratings are high-quality.
The leaderboard then shows the order of best to worst LLM based on each model’s Elo score. The leaderboard table has the following columns:
Model name and a link to more information about it.
Arena Elo score for the particular model which is determined as described above.
The confidence interval that displays the level of confidence in the Elo ranking for that particular model. This is important to show any possible discrepancies in model rankings.
Votes cast for the particular model. Older models will generally have less votes than newer models.
The organization that created the model. It’s always a good idea to keep tabs on what organizations are up to.
The license the model is under. This tells you if the model is proprietary or if it is distributed under a license that allows users access to some or all of the model for their own use.
A model’s knowledge cutoff showing the data the model is trained up to. Most LLMs can only access data up to a certain data until they are further trained.
The leaderboard also has charts to better visualize the data and offers a notebook for you to recreate all tables and visualizations on your own. The notebook allows for excellent data visualizations such as the visualization below displaying both Elo rating and confidence interval.

Why it’s important to understand how the Chatbot Arena leaderboard works
Like I said above, there are subjective elements to some benchmarks and it’s important to know that benchmarks are designed for specific performance metrics. A few reasons its critical to understand this in relation to the Chatbot Arena include:
Understanding confidence intervals. If you look at the leaderboard, you’ll see there are three different models (as of 4/15/2024) in the #1 spot. GPT-4-Turbo, Claude 3 Opus, and GPT-4-1106-preview have all been awarded the top spot. This is because confidence intervals (CIs) are calculated for each model to understand a possible degree of error in the benchmarking process. This means a model with an Elo of 1260 and a CI of +5/-5 may or may not be better than a model with an Elo ranking of 1255. The closeness in performance of those models makes it difficult to distinguish which is considered better. When GPT-4-Turbo came out, every influencer took the chance to announce the news of a new winner on the Chatbot Arena leaderboard. In reality, it took the top spot but just barely.
The Chatbot Arena primarily ranks chatbots. While this is the most prominent use-case for LLMs, chatbots aren’t the only way LLMs are used. It’s important to think about whether a chatbot evaluation is an accurate assessment of LLM performance in other applications.
This Elo rating is created by human comparisons. This by definition makes it subjective and means the leaderboard might not reflect your ranking of these LLMs or their accuracy for every use case. Currently, there is no entirely objective way to compare LLMs.
Understanding licenses is very important. For simplicity, many lump LLMs into two categories: proprietary and open–source. In reality, there are very few open-source LLMs. Instead, most “open-source” LLMs are partially open-source causing many to start referring to them as “open LLMs”. Open-source has a definition many open LLMs don’t fit into. The Chatbot Arena leaderboard shows a model’s license instead of claiming a model to be “open”. This allows you to research the license for yourself.
Chatbot Arena is an excellent resource, but like all benchmarks it’s important to understand what it tells you and what it doesn’t. If you like this overview, let me know and I can do more for other leaderboards and benchmarks.
As always, you can support Society’s Backend for just $1/mo for your first year. It’ll get you access to all my resources including the RSS feeds I use, my notes, and all the resources and updates I collect. I’m also thinking about adding machine learning-related job postings for those looking to develop their career. Let me know if that interests you!
Excellent take!
Just to push back a little bit on one of the claims--and I know what you intended to mean but I'm taking the chance to bring up some debate--there are definitely completely objective ways to evaluate an LLM.
Just pick a task, build a dataset, and run the LLM. Take code generation, for example. It is relatively easy to build a dataset of coding challenges that is completely objective by evaluation the LLM on test cases.
What you mean, of course, is there is no single objective measure to claim one LLM is better than the rest, *in general*. And there will never be, simply because these things have many uses that imply inherent tradeoffs. What we have is an infinite number of meaningful objective metrics, depending on the task you want to evaluate. And of course, we also have many subjective metrics, such as in the Chatbot Arena. That's why there isn't one objective measure to rule them all.
So just wanted to bring that up because it's an interesting discussion, and I'm sure you agree with me.