


How to Use Benchmarks to Build Successful Machine Learning Systems
And what benchmarks mean for real-world applications

Get more of my posts by following me on X and ML and SWE videos by subbing on YouTube. If you enjoy my writing, consider supporting Society’s Backend for $1/mo for your first year. You’ll get occasional extra articles and the full list of resources each week.
Tl;dr: Software engineers building applications using machine learning need to test models in real-world scenarios before choosing which model performs best. Benchmarks are good preliminary measures but don’t reflect the complexities of real-world scenarios.
Goodhart’s Law tells us “when a measure becomes a target, it ceases to be a good measure”. Once a metric becomes a target, it becomes too easy to manipulate data and processes to achieve that target while neglecting important performance metrics ignored by that measure. This is the crisis the machine learning community is currently dealing with.
The release of more frontier models has highlighted a major issue in the machine learning community: benchmarks. Benchmarks are measures of model performance that have become targets for modeling teams. Instead of optimizing models for real-world performance, models are optimized for benchmarks so they can outrank competitors.
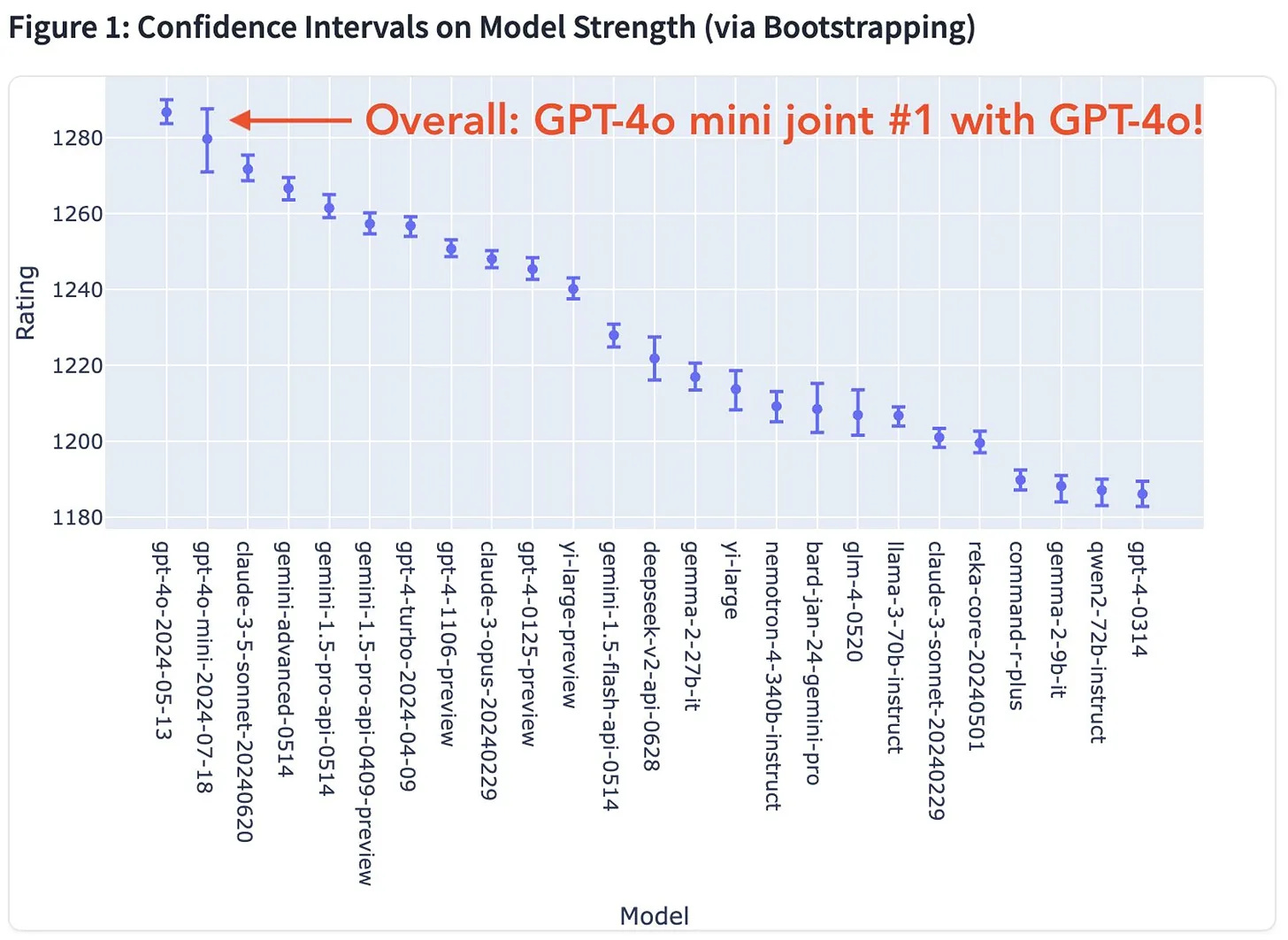
put this really well by calling this “Benchmark Island”: a scenario where AI development becomes detached from real-world applications as models are optimized for unimportant measures.We see this clearly with GPT-4o-mini. It ranks above Claude-3.5-Sonnet on the Chatbot Arena leaderboard. Claude-3.5-Sonnet is widely regarded as the current top-performer for practical applications while GPT-4o-mini has been regarded as underwhelming. OpenAI optimized GPT-4o-mini for measures like ChatBot Arena instead of real-world model performance. If you want to understand how OpenAI did this, why it worked, and what can be done to prevent it in the future, check out this article by
.
This optimization has a very real impact on building AI applications. Benchmarks and leaderboards all claim to show which model is “the best”. As a consumer, a claim like this might be enough but as an engineer building machine learning applications, the nuance of model performance matters. Choosing the right model makes or breaks successful ML applications.
I’ve already written about the importance of understanding what benchmarks actually tell you. This week, let’s focus on how benchmarks can actually be useful when building AI applications. Keep in mind, this is heavily geared toward building with LLMs because that’s what most benchmarks apply to, but the principles are applicable to all types of ML models.
What should engineers understand about benchmarks?
The first thing engineers need to understand about benchmarks is that well-designed benchmarks serve an important purpose. They can be good measures of certain aspects of model performance and can guide AI development and optimization. Benchmarks become poor when they become a target instead of a measure or fail to accurately measure their claims.
Thus, good benchmarks should be:
Relevant: Benchmarks should measure metrics that matter for real-world performance.
Representative: Benchmarks need diverse measures and should cover a wide range of the application space.
Recent: Benchmarks need to evolve with AI. This is something the community is currently dealing with as models have begun to outperform common benchmarks.
Repeatable: Benchmarks should be consistent and reasonable in cost so they can be easily used and assessed.
Benchmarks should focus on measuring a specific aspect of a machine learning model and be clairvoyant about what that aspect is and how it’s measured. It’s often helpful to have community-developed benchmarks to achieve this.
Measurement clarity is especially important because different metrics will be important at different parts of the ML application development pipeline. For example, researchers will likely be focused more on model accuracy while engineers may care more about cost, efficiency, and speed.
If you’re working as a machine learning engineer on a production system, you’ll likely design your own benchmarks and performance metrics specific to your system. Your custom-designed benchmarks should follow the above standards as well.
How benchmarks should be used to build real-world systems
Benchmarks that adhere to the above rules can be useful for building real-world systems. I suggest using them for initial model selection because they allow models to be compared across the same criteria. They also highlight the applications where a model can outperform others.
However, benchmarks fail to capture the complexity of real-world systems and production environments. You should also test models before committing to them. Test edge cases, ease of use, introducing your data pipeline, and context-specific performance before starting to build out a production-level system. There’s a lot of engineering that goes into fitting a model to a system that is difficult to redo if a model is chosen incorrectly.

Testing models provides the following benefits:
Avoids over-optimizing a system for benchmarks. For example, OpenAI’s GPT-4o-mini looks promising based on benchmarks but is much worse than other models in practice.
Avoids choosing a model solely based on one category (i.e. coding when the system may need proficiency in other areas).
Tests how the model works with all aspects of your system (memory, compute, I/O, etc.). A model may perform the best in an ideal environment but work poorly with the rest of the system.
Balances multiple factors to get a better picture of which model is actually “the best”. All models have different pre-training datasets and some may work better for your use case than others.
What should I be testing models for and how should I do it?
You should test a model for the following impacts on your system:
Latency: Check the model latency to ensure it falls within the requirements of your system. This can be a deal-breaker for many applications.
Cost and resource usage: Get a good sense of what the model will cost you. This can be done by comparing API costs, but factors like re-running prompts, tokenization, etc. all play into the real model costs.
Scalability and deployment options: Is this model easy to scale to more users and how easy is it to deploy?
API ease-of-use: If using an API for development, testing will give you a good feel for how easy the API is to use. It may be worth spending a bit more for greater development velocity. Not all APIs are created equally.
Long-term viability (IMPORTANT): Can you trust the company backing the model you’re using to be around and continually support it? Swapping models is a lot of work.
Domain-specific performance: Ensure the model you’re using is good for the purpose you want to use it for. Test the chosen domain rigorously.
Reliability, failures, and downtime: Do you have to re-run prompts frequently? Is the API ever unavailable? These are all factors that greatly impact real-world systems that aren’t as heavily considered in research applications.
There’s no cut-and-dry answer for how you should test for these factors, but my suggestion is to start in a testing playground and then build a smaller version of your target system that tests the core functionalities. For example, if you’ll be fine-tuning the model in your production system, you should test fine-tuning the model in your smaller system. Even better if you can spin up the smaller system in a production environment and see how it performs and the practicality of maintaining it.
All of this requires human evaluation of the outputs of the system, but you can also directly compare model choices using something like LLM-as-a-judge.
Don’t put too much faith in benchmarks. They’re gameable and aren’t representative of the complexities found in real-world applications. As machine learning engineers, the real-world applications are what we focus on. If you have any questions, always feel free to reach out.
Thanks for reading! If you enjoy content like this, don’t forget to subscribe on YouTube.
Always be (machine) learning,
Logan