


ML for SWEs 6: RAG Is Not Dead
Machine learning for software engineers 4-11-25

The hardest part about working in AI and machine learning is keeping up with it all. I send a weekly email to summarize what's most important for software engineers to understand about the developments in AI. Subscribe to join 6500+ engineers getting these in their inbox each week.
If you want to learn machine learning fundamentals, check out my roadmap!
Always be (machine) learning,
Logan
Llama 4: Meta has disappointed the AI community
The largest news this week was the release of the Llama 4 family of models from Meta. Interestingly, they were released on a Saturday (so almost a week ago) which is unusual as weekend releases tend to make less of a buzz in the AI community.
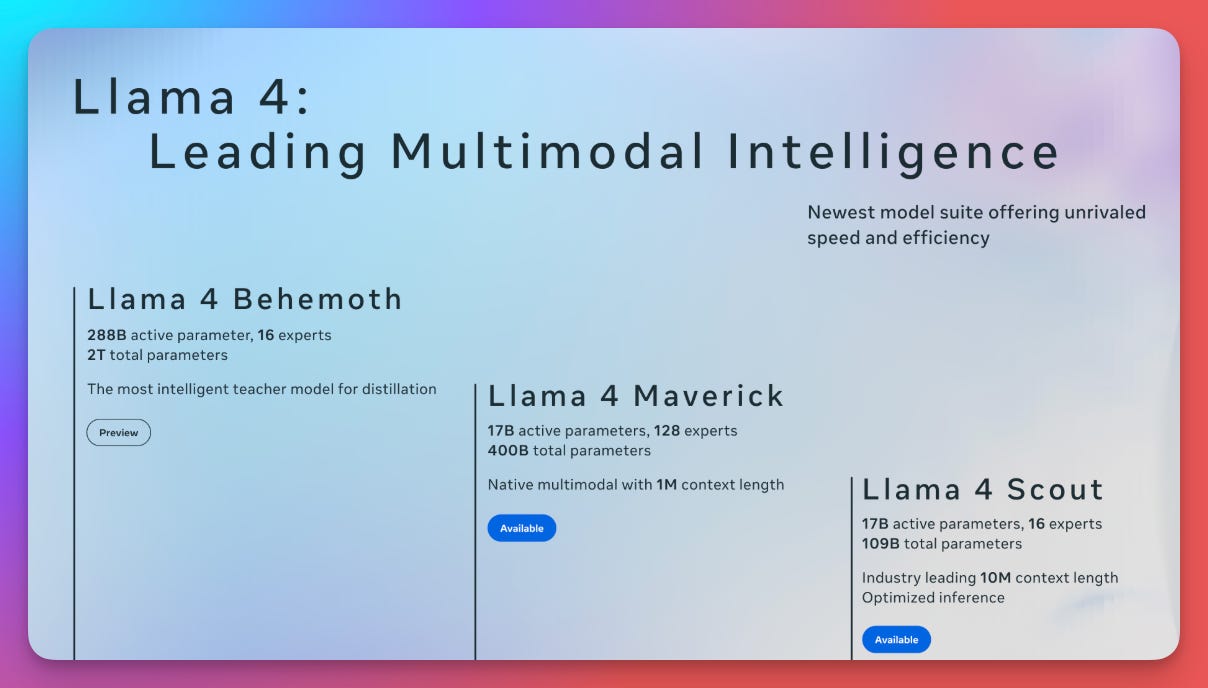
The Llama 4 “herd” includes 3 models: Scout, Maverick, and Behemoth. Scout and Maverick both have 17 billion active parameters, with Scout utilizing 16 experts and Maverick utilizing 128. Scout supports a 10 million token context window (more on that in the next section) which is 10x Gemini’s already incredibly large context window. Maverick excels in image understanding and coding tasks. Behemoth, which will be the largest model of the Llama 4 herd, is currently training so it has not yet been released.
Benchmarks boast the Llama models beating all competitors except Gemini 2.5 Pro (which is absolutely cracked), but real-world testing is telling a different story. The biggest takeaway from the Llama 4 models so far is that they’re a disappointment. There are many theories of benchmark manipulation to make the models look better than they actually are. Meta says these theories are simply not true.
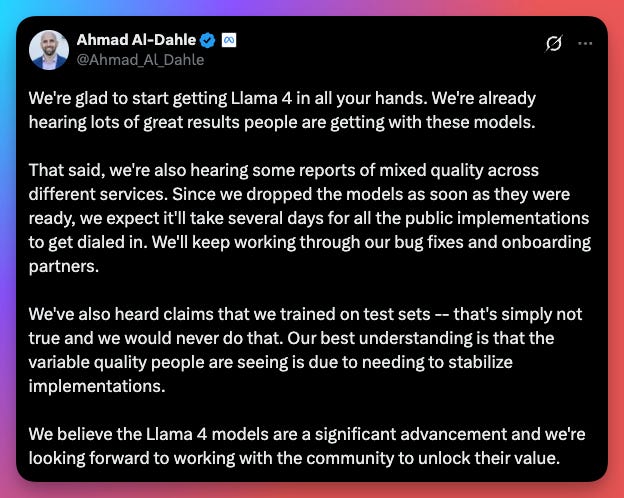
Two more disappointments: 1) The license for the Llama 4 models are highly restrictive and 2) The models have been criticized for not being able to be run on consumer hardware. Sure, it can be run on multiple 4090s, but most consumers don’t have those sitting around. One of the things that made previous Llama models beloved by the AI community was the ability to easily run them on consumer hardware and a freedom for what developers can do with them.
The takeaway from this release is a lack of clear narrative from Meta. They release seems to have hurt their competitiveness in AI. It’s almost as if they rushed out the models due to recent releases from their competitors.
RAG is not dead
Because Scout has a 10 million token context window the “RAG is dead” narrative is alive again on social media. I want to repeat that this isn’t the case. If you work as a machine learning engineer, it’s likely you’ll need to use RAG at some point and it’s important for you to understand that RAG is not dead. Anyone saying this misunderstands the purpose of it.

Fundamentally, RAG is a way to retrieve information that is needed to provide context to an LLM. The way this is done is by retrieving the information (wherever it may be stored) and appending it to the LLMs context window. With small context windows, a large part of this process is efficiently fitting that information (which could be massive) into the size of the window.
However, large context windows don’t make RAG any less important. First, the retrieval part of RAG will always be relevant. Retrieving information and appending it to a request will always (barring crazy advancements) be a method of providing LLMs information.
Second, RAG will still be used with long context windows. Long context windows are not infallible. Attention mechanisms have their limitations. Studies show that LLMs have a hard time understanding where within a long context window information should be found. This results in LLMs struggling to retrieve information in the middle of a given context. In this case, efficiently providing context to the LLM (such as RAG does) is still important.
Also, there are many use cases (such as personalization) where we have more information to give to an LLM that can be packed into a one or ten million token context window.
Google releases an inference-only TPU
Ironwood is Google's latest TPU, designed specifically for inference, providing significant advancements in performance and energy enabling massive parallel processing capabilities essential for large AI models.
I’m including this for two reasons: 1) It’s really cool and 2) Not relying on someone else to provide the hardware for their AI has paid dividends for Google. In fact, the decision to start developing in-house TPUs in the 2010s might just be the most forward-looking business decision of that decade.
We’ve seen the dividends of Google’s TPU development recently with Gemini 2.5 Pro smashing benchmarks and leaving the competition behind. If you follow me on other social platforms, you’d know I’ve been posting about it a lot. I’m really hoping OpenAI comes out with something comparable soon to continue pushing the development at both companies.
More for developers
Here a few more things that are of interest to software developers:
Google releases an AI IDE: Google has launched an AI-powered integrated development environment (IDE) called Firebase Studio, enhancing web-based development with AI assistance.
Veo 2 is now available in the Gemini API: Veo 2 is now accessible to developers through the Gemini API, allowing video generation with text-to-video and image-to-video features for those with billing enabled.
Anthropic is still giving out $50k in free API credits for developers to experiment with Claude.
That's it for discussion topics this week! Thanks for reading. If you missed last week's ML for SWEs update, check it out:

Below are my picks for articles and videos you don't want to miss from this past week. My entire reading list is included for paid subs. Thank you for your support! 😊
If you want to support Society's Backend, you can do so for just $3/mo.
My picks
A Prompt Engineering Guide from Google: Prompt engineering is the process of crafting effective input prompts for large language models to ensure accurate and meaningful output, considering factors like model type, training data, and word choice.
How to Stay Sharp on AI Without Burning Out by
: To stay updated on AI without burning out, it's essential to adopt an efficient learning system that allows for quick comprehension and application of complex topics while balancing professional and personal commitments.Beyond vibe checks: A PM’s complete guide to evals: Mastering evaluations (evals) is crucial for AI product managers, as they provide the insights needed to ensure AI systems perform effectively and meet user expectations.
How I Became a Machine Learning Engineer Without an Advanced Degree by
: Logan Thorneloe shares his six-year journey to becoming a machine learning engineer at Google without an advanced degree, emphasizing the importance of strategic planning, networking, and seizing opportunities in education and internships.Nonproliferation is the wrong approach to AI misuse by
: Focusing on leveraging adaptation buffers to implement defensive measures is a more effective strategy for managing the risks of catastrophic AI misuse than relying on nonproliferation.There Are No New Ideas in AI… Only New Datasets: AI progress primarily stems from leveraging new datasets rather than groundbreaking ideas, suggesting that future advancements will likely depend on unlocking and utilizing previously untapped sources of data.
Keep reading with a 7-day free trial
Subscribe to Society's Backend to keep reading this post and get 7 days of free access to the full post archives.