


An Overview of Text Summarization Methods from Simple to Complex
And why LLMs might not be your best option

We went through a bit of a rebrand. Let me know what you think about Society’s Backend’s new color scheme and logo! :) - Logan
I've been researching text summarization methods for a project I'm working on. Since the advent of Large Language Models (LLMs), LLMs have become a go-to solution, even making their way into the Google app with Bard. It's no wonder, given our era of information overload, that the ability to create concise, natural, and accurate summaries is super useful.
While LLMs are gaining popularity, my research has revealed that they are not always the optimal solution for summarizing information. Despite their prowess, there are numerous other efficient methods available.
I go over many of these methods below. The explanation of each will be simplified for a more basic understanding and this will ensure I don’t write a novel.
Manual Summarization
Before delving into software-based algorithms, it's valuable to understand the manual summarization techniques we use daily. These techniques act as the building blocks of more advanced solutions. These include:
Using titles and headings: These serve as natural summaries.
Heuristic approaches: For example, selecting the first sentence of each paragraph or identifying key terms.
Template-based summarization: Extracting specific information to fill a predefined template.
Syntactic parsing: Analyzing the structure of sentences to identify key information.
Semantic parsing: Interpreting the meaning of words and sentences for summarization.
Automatic Summarization
Programmatic summarization falls into two main categories:
Extractive Summarization: This simpler method uses algorithms to select important words and sentences directly from the source material.
Abstractive Summarization: This method generates new sentences for summarization and relies on machine learning.
Some methods use a combination of these two, but that’s for another article.
An Overview of Simple Keyword Extraction
The following is a straightforward keyword extraction algorithm, provided courtesy of ChatGPT. The steps include:
Word Segmentation: The algorithm divides the entire text into individual words.
Frequency Analysis: It then counts how often each word appears in the text.
Keyword Identification: The most frequently occurring words are selected as the primary keywords.
Sentence Selection: The algorithm identifies sentences that include these keywords.
Summary Composition: These selected sentences are compiled to form the summary.
Below is a Python implementation of this algorithm, utilizing the Natural Language Toolkit (NLTK):
import re
from collections import Counter
from nltk.tokenize import sent_tokenize, word_tokenize
from nltk.corpus import stopwords
import nltk
# Download necessary NLTK data
nltk.download('punkt')
nltk.download('stopwords')
def summarize_text(text, num_keywords=5, num_sentences=3):
# Convert text to lowercase and tokenize into words
words = word_tokenize(text.lower())
# Filter out stopwords and non-alphabetic words
stop_words = set(stopwords.words('english'))
words = [word for word in words if word.isalpha() and word not in stop_words]
# Calculate word frequencies
word_frequencies = Counter(words)
# Choose the most common words as keywords
keywords = set([word for word, freq in word_frequencies.most_common(num_keywords)])
# Split the text into sentences
sentences = sent_tokenize(text)
# Rank sentences based on keyword presence
ranked_sentences = sorted(sentences, key=lambda s: sum(word in s.lower() for word in keywords), reverse=True)
# Select the top sentences for the summary
summary = ' '.join(ranked_sentences[:num_sentences])
return summary
# Demonstration of the function
input_text = "Your input text goes here. It can be a paragraph or a full article. The algorithm will identify the most frequent keywords and select sentences containing these keywords for the summary."
summary = summarize_text(input_text)
print(summary)While this method is effective, its performance can be further enhanced by considering the semantics of the text and the ordering of sentences. Additionally, other machine learning libraries beyond NLTK offer more sophisticated keyword extraction. The success of this approach is closely tied to the structure of the text and does much better when key ideas and associated keywords are frequently reiterated.
A notable challenge is dealing with frequently repeated but non-essential words. For instance, while common words like 'the' and 'a' are filtered out using NLTK's stopwords, what about non-stopwords that are frequently repeated but not central to the text's main theme? This is especially pertinent in summaries spanning multiple documents on similar topics, where such words could disproportionately influence the summarization. This led me to further explore more advanced methods of keyword extraction.
TF-IDF: Enhanced Keyword Identification Across Documents
TF-IDF, or Term Frequency-Inverse Document Frequency, enhances the basic method of keyword frequency counting. It operates by first determining the frequency of a word within a document (Term Frequency, or TF), calculated as the count of the term (t) divided by the total number of terms in the document (d):

The approach then shifts to consider how often a term appears across multiple documents. Inverse Document Frequency (IDF) works on the principle that terms common across many documents are poor discriminants of key ideas. Therefore, IDF penalizes words that are frequent in a larger document set. The IDF formula is:
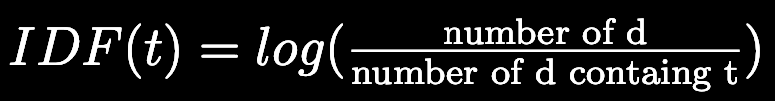
Combining these two metrics, the TF-IDF score for a term in a specific document is calculated as the product of TF and IDF:

This resultant score is used to extract keywords from a document, which are then used to select sentences for summarization. The strength of TF-IDF lies in its ability to effectively pinpoint keywords in large document sets via a straightforward calculation. However, it does have shortcomings, such as its inability to interpret the semantic meanings of words and the potential to undervalue significant keywords that are common across many documents.
Despite the emergence of more sophisticated models that offer greater accuracy in keyword extraction and summarization, TF-IDF maintains its popularity due to its simplicity and efficiency. Moreover, it serves as a foundational technique in various other summarization methods, which we explore next.
LexRank: A Graph-Based Approach to Sentence Extraction
LexRank stands out as an unsupervised machine learning algorithm for summarization that leverages graph theory. It constructs a relational graph linking sentences within a text and assigns importance to them, using a ranking method akin to Google's PageRank algorithm.

The LexRank process involves several key steps:
Data Preprocessing: This includes breaking down the text into individual sentences and applying methods to streamline the data, such as removing stopwords.
Create Sentence Embeddings: Sentences are transformed into numerical vectors using algorithms like TF-IDF or Word2Vec.
Graph Construction: A relational graph is created based on the similarities between the vectors. Connections, or edges, between sentences are established based on their cosine similarity, adhering to a predefined similarity threshold.
Sentence Importance Scoring: Similar to PageRank, LexRank uses eigenvector centrality to score sentences, considering a sentence more significant if it is connected to other important sentences.
Selection of Key Sentences: The algorithm picks sentences with the highest LexRank scores for the summary, with the number of sentences chosen based on a set threshold.
Summary Composition: The chosen sentences are then put together to create a summary. Post processing may be used to ensure cohesiveness and remove repetition.
One of LexRank's advantages is its use of original sentences from the text, ideal for cases where retaining the author's exact phrasing is crucial. It excels due to low data and compute requirements and its unsupervised nature, but can struggle to summarize documents on diverse topics due to way it relates sentence embeddings.
Essentially, LexRank is particularly effective when the primary goal is to extract key information from documents, with less emphasis on narrative continuity or paraphrasing.
Seq2Seq: Utilizing Deep Learning for Text Summarization
The Sequence-to-Sequence (Seq2Seq) model utilizes deep learning and employs a neural network with an encoder-decoder structure for creating text summaries. The encoder stage of Seq2Seq processes the input text into a vector representation. The decoder then reconstructs this encoded information into a summarized form. This approach uses recurrent neural networks (RNNs), often Long Short-Term Memory (LSTM) networks.

In Seq2Seq, the neural network learns through a process known as supervised learning. The supervised learning process follows these steps:
A body of text and its expected summary are fed into the model.
The model uses the input text to generate a summary.
The model adjusts its parameters (weights) based on how close the generated summary was to the expected summary.
This is done thousands of times over thousands of text and summary inputs until the model is producing proper summaries.
This training process allows Seq2Seq to generate highly accurate abstract summaries, creating its own sentences rather than just extracting them from the original text.
However, there are notable drawbacks:
Significant computational resources are required for the extensive training process, typically involving Graphics Processing Units (GPUs), which can be costly and time-consuming.
The quality of the generated summary heavily depends on the quality and relevance of the training data. Inaccurate or biased training data can lead to poor model performance.
As a supervised learning model, Seq2Seq requires large amounts of pre-summarized text for training, possibly requiring manual curation.
For longer summaries, the model might need additional mechanisms like attention to maintain the context and coherence of the generated text.
The next summarization method utilizes attention and the encoder-decoder model to improve upon Seq2Seq’s summaries.
LLMs: Using Transformers for Text Summarization
LLMs are increasingly popular for their exceptional summarization abilities. I know many people who use ChatGPT primarily to summarize information. If you want to understand the value of LLMs for summarization, visit chat.openai.com or bard.google.com and ask them to summarize this article. The results are remarkable.
Like Seq2Seq, LLMs are supervised machine learning models, but differ from Seq2Seq models in two main aspects. Firstly, LLMs are trained to predict the continuation of a given text instead of predicting a summary based on input text. This means an LLM's input is text and the continuation of that text instead of text and its summary.
Secondly, LLMs require significantly more training data than Seq2Seq. Their design necessitates extensive training on vast datasets and many more network parameters to thrive in ambiguity and understand nuance. While a typical Seq2Seq model might have around 3 million parameters, GPT-4 (the model behind ChatGPT) contains approximately 175 billion parameters. For a visual representation of this, the white dots on each side of the below graphic represent the comparative number training parameters for each model:

If you really squint, you can see Seq2Seq’s training parameters. And no, there’s no background visible on the GPT-4 side.
The advantages of LLMs include their ability to:
Accurately summarize text regardless of content.
Generate abstract sentences akin to human writing.
Understand nuances such as summarizing specific topics or creating summaries of desired lengths.
Versatility in performing tasks beyond summarization.
However, high-quality LLMs are expensive to train leading to a reliance on larger companies that can afford to do so. Additionally, the computational cost for serving an LLM is high compared to models like Seq2Seq where the computational cost is felt primarily during training.
Why does this matter?
One of my favorite things about the field of computer science is algorithms that perform better aren't always considered better. Factors such as computational cost, reliability, scalability, and availability play crucial roles in evaluating software systems. This means that even as more accurate algorithms emerge as computer science advances, older algorithms often remain in use due to their specific advantages in certain scenarios.
For users and developers of summarization tools, it's essential to understand the mechanics of how these tools summarize information. Key considerations include:
Accuracy and reliability of the summarization.
Whether the tool creates new sentences or retains the author's original phrasing, and how accurately it maintains the writer's intent.
The types of content (such as genre and length) that can be effectively summarized, and the level of detail that can be maintained.
The cost associated with using the summarization tool.
Awareness of these aspects helps in making informed decisions about which summarization technique to employ. LLMs are at the forefront of this technology, offering state-of-the-art capabilities, but they're expensive. In some instances, the premium for their performance may not justify their use over other methods.
The need for efficient summarization will only grow and understanding the summarization methods available will be increasingly vital. Let me know if you have any questions about the methods listed above.
Spotlight
This week I’m spotlighting The Tech Writers Stack. It’s an incredibly supportive group of writers who write on all sorts of tech-related topics. If you’re interested in writing about tech, join us on Substack. :)

If you’d like to be in the next Spotlight, reach out to me on X or LinkedIn. I’m going to share work I enjoy each week.
Always feel free to reach out with any questions or just to chat.
If this article impacted you, please subscribe and share it with your friends. Thank you for supporting my writing!

If you’re already a free subscriber, you can support me for just $5 a month.
That's awesome, and really clear. Thank you.
I've been thinking about this recently in terms of a map like the one described here, a graph of 80k distinct concepts: https://www.numind.ai/blog/a-foundation-model-for-entity-recognition
I'm imagining being able to visualize the location of a text on a graph like that, then see the way it ramifies as you summarize/represent it at different levels of granularity (document, chapter, section, paragraph, sentence, etc.)
It could offer a way to discover adjacencies in a library of texts, too, like RAG to find other texts with threads adjacent to what you're currently reading.
Great article! TF-IDF is one of those rare ideas that is at the same time Simple and Powerful