


Why Machine Learning Technical Debt is Especially Bad
And effective ways to mitigate it

I was chatting with my manager a few months ago about the technical debt within my team's codebase and how we can fix it. Every software engineer knows about and has worked with technical debt. For those unfamiliar, technical debt is simply the way old code and design decisions impact the addition of new code and features in a software system. It's called debt because it tends to get worse as time goes on if left unaddressed.
All software systems deal with technical debt to a certain degree. Proper planning and execution of adding code and features helps mitigate the impact technical debt has, but a lot of it is unavoidable and is due to the way a system develops as it succeeds or as technology progresses.
In machine learning, technical debt is compounded because machine learning not only relies on the same software engineering that brings technical debt to traditional software systems, it also relies on the machine learning-specific components that build their own technical debt. I was speaking with my manager because I wanted to learn more about the general strategies employed to mitigate this machine learning-specific technical debt.
He pointed me to a publication that describes machine learning technical debt as the high-interest credit card debt of technical debt. This paper does an excellent job of explaining the difficulties of ML systems that lead to technical debt and some ways to avoid it. The explanations within the paper fit perfectly with what I've experienced at work and helped me understand why the technical debt my team deals with exists.
My manager kindly pointed out the reason for this: some of the authors of the paper are my teammates. I was reading a paper written by my coworkers derived from the system I work on every day. I found this paper so impactful, I'm going walk through it to clarify and simplify it's explanations. This is important information for anyone working on a machine learning system to understand.
ML-Specific Technical Debt
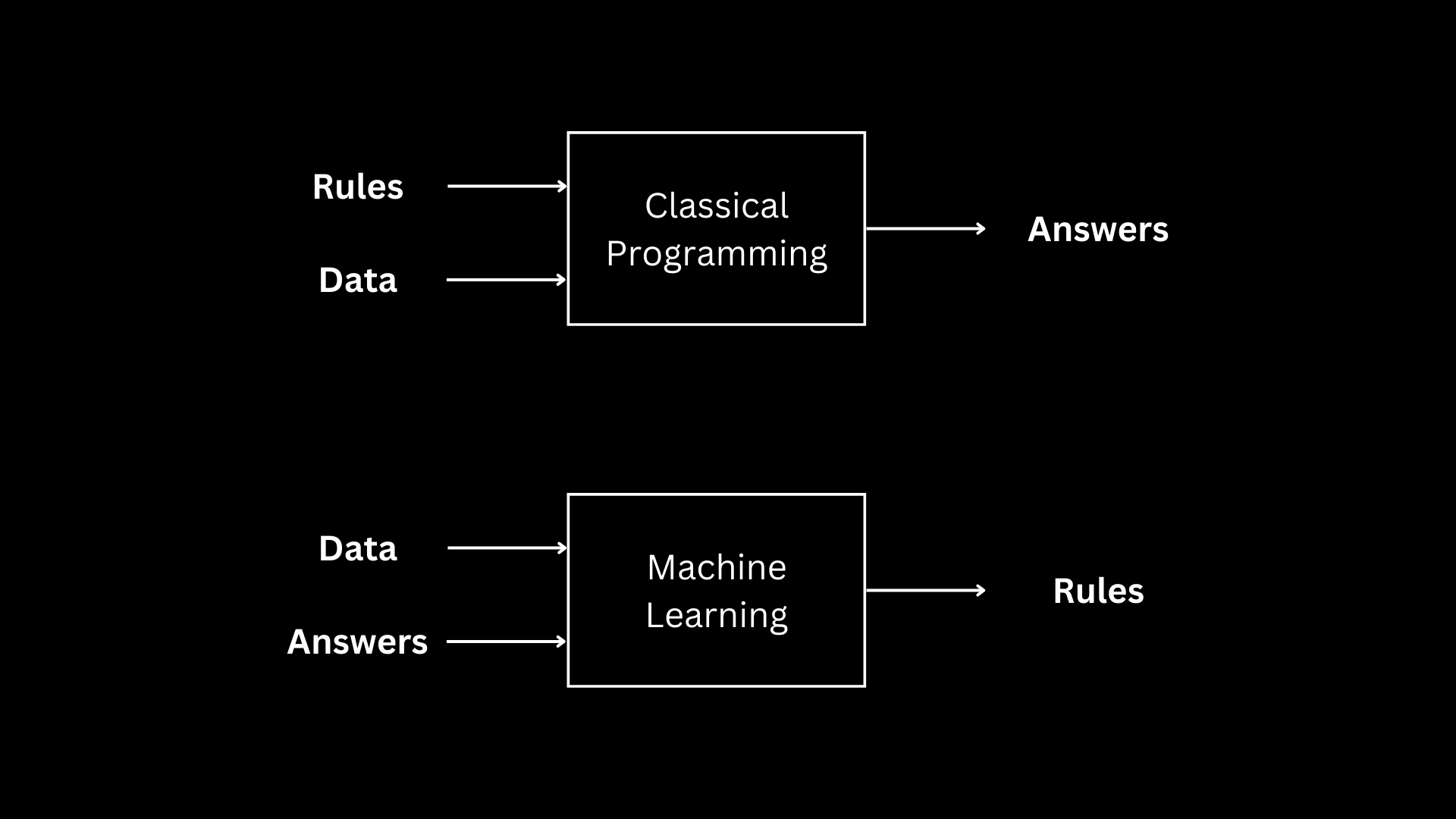
The first thing to understand about machine learning-specific technical debt is that most common methods for paying down technical debt for traditional software systems don't apply to machine learning systems. I've included the below graphic to help show why this is. In traditional programming, we give a system rules and data and the system uses those rules and data to give us answers. In machine learning, we give a system data and answers and tell it to figure out the rules for itself. These rules are then used to figure out answers for other inputs.
Technical debt has been addressed in software systems for decades which has developed best practices for dealing with it; however, the difference in problem-solving between traditional software systems and machine learning makes it difficult to apply these time-tested practices to machine learning systems. The primary reasons for this are:
An inability to delineate machine learning system boundaries.
The heavy reliance on data dependencies for machine learning systems to function.
Machine learning systems influencing themselves via feedback loops.
Anti-patterns within the non-ML pieces of a ML system.
Configuration complications.
System Boundaries
Classical programming makes addressing technical debt easier by using a concept called abstraction. Abstraction separates core functionality into different pieces of a system to make changes in the functionality of one aspect of the system independent from changes in another. Essentially, this allows engineers to make changes to the system logic without worrying about the impact those changes will have in other areas.
This doesn't work in machine learning systems. Precisely what makes machine learning systems so valuable is their ability to solve problems in situations where logical systems aren't able to. Logical systems can abstract their logic into separate functional pieces of a system. Machine learning is often used to solve difficult real-world problems that don't fit into tidy encapsulation. Thus, abstraction can't be used to separate logical pieces of the system and can't be used to manage technical debt.
Here are some examples of how the lack of system boundaries in machine learning systems contribute to technical debt:
Entanglement: The features within machine learning systems aren't truly independent. A change to one feature within a system can cause others to change as well making the isolation of improvements impossible. The paper talks about the CACE principle: Changing Anything Changes Everything. This makes it impossible to delineation boundaries in the system to mitigate technical debt.
Undeclared consumers: Since machine learning systems rely so heavily on data, it can be really easy to pull signals from wherever they can be found. For example, a model might store its output and another model might access that output to create its own especially if specific access controls aren't in place. A dependency like this can create complex feedback loops that make isolation pieces of a system difficult.
Data Dependencies
Machine learning systems require a considerable amount of data handling and management to work properly. This introduces data dependencies, which create technical debt. Traditional systems deal with a lot of code-related technical debt. Tools such as compilers and linters help address these issues. The same tools don't exist for data-dependent technical debt.
Data-dependent technical debt arises from:
Unstable inputs: Data inputs need to be stable to ensure proper functionality for machine learning systems. Inputs from other models (as described above), or from any data source that can be changed over time, create instability that can add to technical debt. This requires infrastructure to closely monitor data sources, which becomes increasing difficult at scale.
Underutilized data dependencies: Programs are often left with dependencies that are unused and therefore unneeded. Similarly, machine learning systems can end up with input data and features that are no longer contributing to model performance. This adds unnecessary data dependencies that can lead to greater technical debt. The way to address this is to run leave-one-feature-out evaluations frequently.
Feedback Loops
One of the features of machine learning systems is they often influence their own behavior as they update over time. This creates feedback loops that continually cause machine learning models to affect one another and make it difficult to predict system behavior before release. The paper calls this analysis debt.
For example, two different stock market prediction systems from different companies may influence one another through their bidding and buying practices. As one bids and buys stock, the other may use those purchases to improve its own bids and buys. This will then affect the first system. This will continue as long as both systems are running. This begs the question: How do we properly analyze machine learning systems when we don't know how they'll impact themselves and address the technical debt that may introduce?

ML System Anti-Patterns
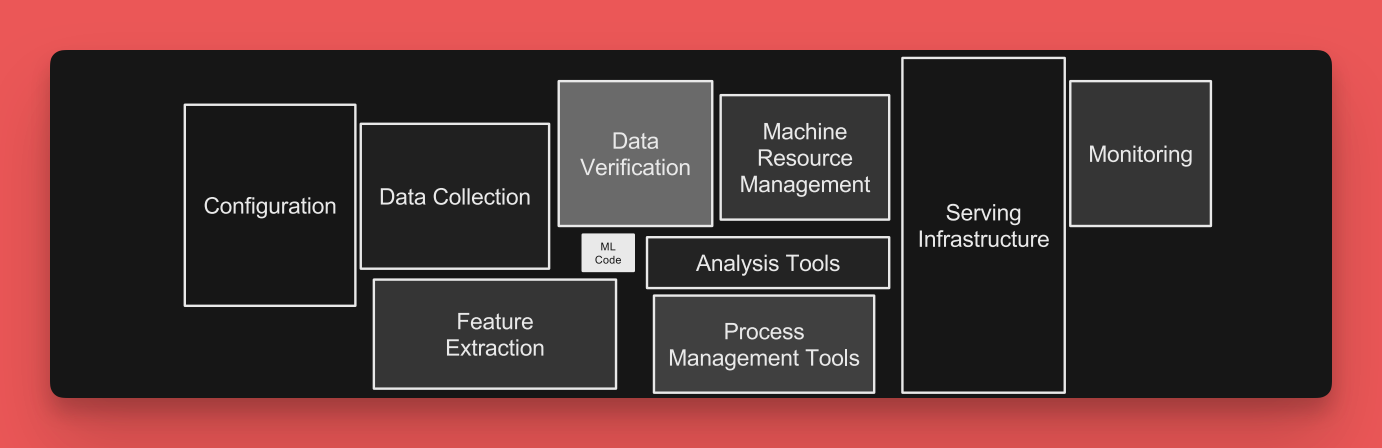
So little of a machine learning system actually consists of the code running learning and prediction. Most of the code are traditional software systems that support the training and serving processes. The diagram above shows the actual learning code in the white box and the supporting processes in the boxes surrounding it. There are many anti-patterns within the surrounding processes that contribute to machine learning technical debt:
Glue code: Gluing together many different generic packages to create a machine learning system can be detrimental to overall system performance. Each of the different boxes above can be dependent on external changes, each has their own method of testing, and each can influence the way the machine learning system is built by forcing the system to conform to its needs. This is why many machine learning systems use bespoke code to ensure control over the entire system.
Pipeline Jungles: As previously mentioned, data is the most important aspect of a machine learning system. If there isn't careful thought put into data collection and management, a system will often end up with many different data collection, joining, scraping, and sampling pipelines that all create their own technical debt.
Dead Codepaths: Many machine learning systems need to be flexible to service many types of experimentation. A way of building this flexibility is to duct tape in conditionals for each experimentation path instead of carefully planning how that experimentation should be introduced and managed. This may be good for quickly adding one experimentation path, but once many different paths are added, significant technical debt is created. More code paths now need to be maintained and those that aren't become dead paths that are still part of the system. The paths to maintain contribute to technical debt and the dead paths can even contribute to errors in production (see Knight Capital's system that lost them $465 million in 45 minutes as an example).
Configuration Debt
A common concept in machine learning systems is configurations--or the ability to change system options when training a model. This becomes costly when thought isn't put into how configuration should occur. Here's an excellent example from the paper for when configuration becomes complex and can create problems:
Consider the following examples. Feature A was incorrectly logged from 9/14 to 9/17. Feature B is not available on data before 10/7. The code used to compute feature C has to change for data before and after 11/1 because of changes to the logging format. Feature D is not available in production, so a substitute features D′ and D′′ must be used when querying the model in a live setting. If feature Z is used, then jobs for training must be given extra memory due to lookup tables or they will train inefficiently. Feature Q precludes the use of feature R because of latency constraints.
These changes can make it difficult to properly configure a model without taking many extra steps to ensure all considerations are taken into account. Misconfigurations not only cost developer and training time, but are also expensive from a resource standpoint and build technical debt that is difficult to fix.
Closing
I'd recommend reading the entire paper as I learned a lot about why technical debt is so bad in machine learning systems. I'll call out one thing that was repeated frequently: a lot of managing technical debt is creating a productive relationship between the engineers and researchers building the machine learning system(s). For instance, the branching code paths example above can be mitigated by proper collaboration between engineers and modelers.
Something I'd also like to highlight is that most of the topics covered in the publication refer to the machine learning system for a single model. All these issues become even more prominent when you consider a company's entire fleet of machine learning models that are training and serving. This also increases the rate at which technical debt accrues.
The last thing I'd like to highlight is a quote at the end of the publication:
Paying down ML-related technical debt requires a specific commitment, which can often only be achieved by a shift in team culture. Recognizing, prioritizing, and rewarding this effort is important for the long term health of successful ML teams.
If you're interested in machine learning engineering, you work on ML, or you want to work on ML, subscribe to Society's Backend and I'll send you a 5-min read once a week to help improve your ML engineering knowledge and skillset. I also send out summaries of recent ML developments and educational resources I find.
You can also support Society's Backend for just $1/mo and get access to all my resources and paid articles.