


A Fundamental Overview of Machine Learning Experimentation [Part 1]
And how it differs from the software development you're familiar with

I’ve wanted to write about machine learning experimentation velocity for a long time because it’s the key for AI companies to beat their competitors, but it’s rarely discussed. It’s what I work on at Google and it has very real implications for how impactful AI is in everyone’s life.
Before we can get into the building blocks of excellent machine learning experimentation, you need to understand how it fundamentally works. I’m going to write about velocity in two parts:
This article will explain machine learning experimentation.
The next article will explain the 3 key principles for successful machine learning experimentation including how AI companies outcompete at scale.
Make sure to subscribe to receive the second part of this article. You can also keep up with my work on X or LinkedIn if newsletters aren’t your thing.
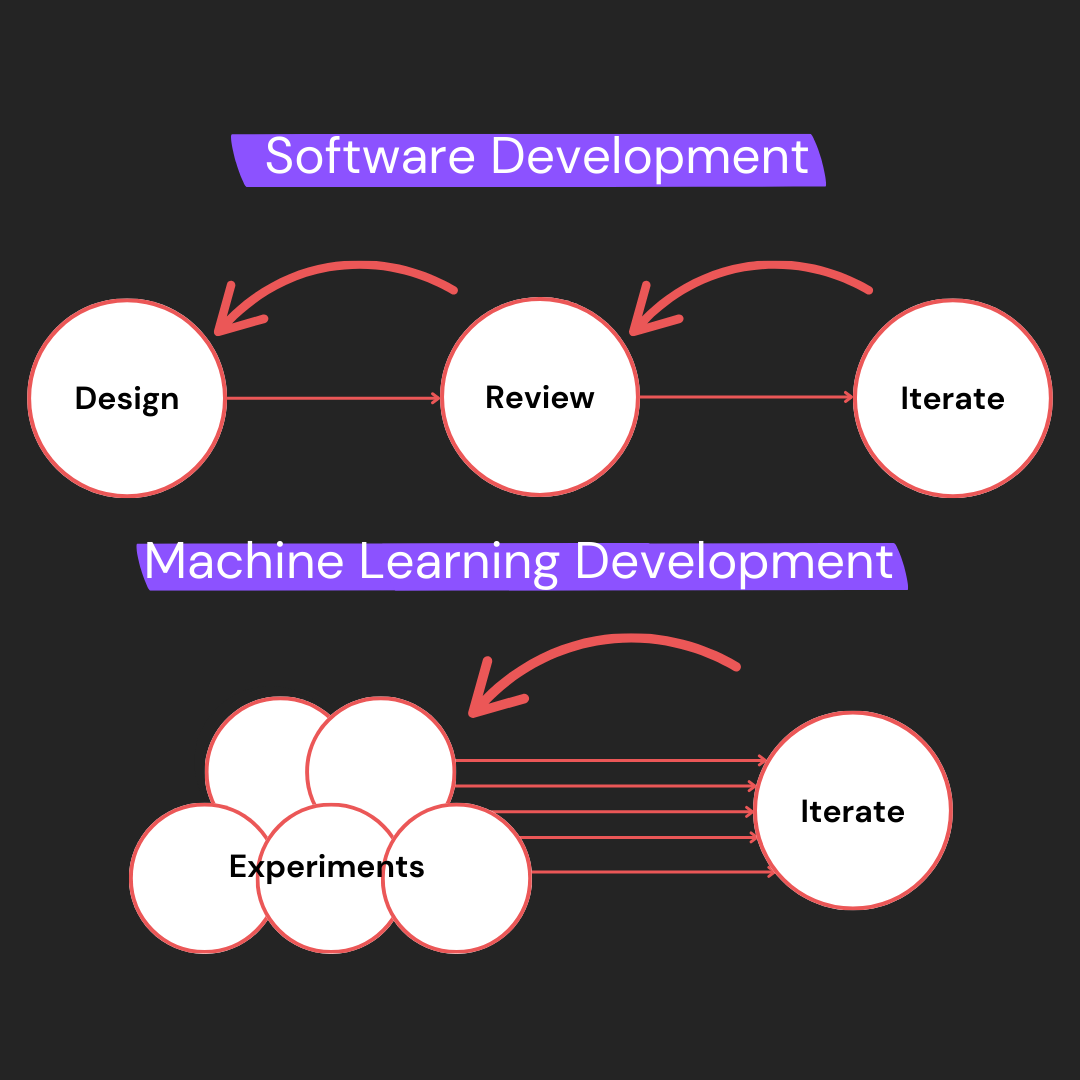
Machine Learning Experimentation
If you’re reading this, I’m guessing you’re likely familiar with the process of software development. Software development requires three primary stages: design, review, and iteration. Those stages usually happen in that order, but iterating may require more designing and reviewing.
When designing software, there’s a good idea of how the system will behave and a straightforward process for ironing out kinks. Software can be made deterministic which makes this process easier. Engineers are familiar with this process and understand how it works and how to make it fast and effective.
This process is also important because the general public has become familiar with it. Their understanding dictates what they know is and isn’t possible to do to improve the software they use. This dictates their expectations for how software companies will improve services and a timeline for how long it will take them to do so.
Machine learning systems work differently. The usual iterative system for building software services breaks down when machine learning models are introduced. This means all the processes we use (and the public are familiar with) to build reliable software quickly are thrown out the window. I’ve written more in-depth about this in another article if this interests you.
The process for designing machine learning models is less like traditional software development and more akin to research science. There’s a reason those developing machine learning models are called machine learning research scientists—it’s because their job is less about engineering and more about experimenting.
Machine learning models don’t improve via a design process, they improve through an experimentation process. Those with a background in machine learning use their knowledge to propose hypotheses about how a model can be improved. They then run an experiment to validate their hypothesis.
This experiment includes training a model with new parameters/data/architecture (whatever hypothesis is being tested) and validating the outcome. This outcome can be favorable and show improvement, it can be partially favorable and require more testing, or it can be unfavorable in which case further hypotheses need to be tested.
At companies with many AI models, each model is improved via this experimentation process. That means for each model, many training runs are done and validated to improve model performance. Many hypotheses are tested requiring the ability to train each model many times.
This is why machine learning modeling is so expensive. It isn’t only because training a model is expensive, it’s because iterating upon that model requires training it many, many times. At scale, experimentation is the focus, not just training. I rarely see this discussed—it seems the focus of better machine learning is having more training chips when in actuality that’s just the beginning of optimizing machine learning at scale.
If you want to work in machine learning at the scale most companies do, it’s key to understand the experimentation process because it:
Includes more than just training.
Shows how machine learning systems differ from software systems and the very real impact that has on engineers, scientists, and users.
Shows that machine learning is expensive not just because training is expensive but because training a single production model requires training it multiple times over.
Thanks for reading! Don’t forget to subscribe to get the next article in your inbox. If you liked this article and know someone else that would enjoy it, please share it with them!
Always be (machine) learning,
Logan
These are some of my favorite insights from you.
Once you throw a bunch of these together, you should come on AI Made Simple for a guest post combining them. It will be super useful to everyone.
Nice work, Logan. Your enthusiasm and clarity make a great one-two punch. It’s significant that machine learning improves not through rational extensions of engineers but through hypothesis testing. This approach would help in education where theoretically grounded experiments integrating AI into writing tasks could examined. There is a lot of hypothesizing but little scientific evidence. For example, I have a hypothesis about prompted writing assignments which could answer a core question about learning loss.