


The Method Google Used to Reduce LLM Size by 66%
A brief overview of knowledge distillation and its capabilities

Google released a technical report on Gemma 2, the next generation of their open LLM. The report is an excellent case study for knowledge distillation as they compare training Gemma 2 from scratch to training it using knowledge distillation. This isn’t the first time we’ve seen knowledge distillation used to train LLMs (Vicuna, Orca, and more - thanks to
for bringing these to my attention), but the report is a great case study for utilizing knowledge distillation to train LLMs.Tl;dr:
Knowledge distillation is a model training method that trains a smaller model to mimic the outputs of a larger model. This has the potential to train up to 70% smaller models while only losing 3-10% performance compared to their larger counterparts.
Google’s Gemma 2 shows that distilled models can perform better than models of the same architecture (and size) trained from scratch.
Google used knowledge distillation to reduce the size of their open LLM Gemma 2 from 27B parameters to 9B parameters while retaining 96% user satisfaction.
Knowledge distillation is an excellent example of how machine learning can make software development easier. It showcases the ability to code one model and train it for different tasks by only adjusting data.
What is Knowledge Distillation?
Knowledge distillation (also known as teacher-student training) is the process of training a smaller model by teaching it to mimic the outputs of a larger model. In traditional LLM training approaches, smaller LLMs would be trained the same way larger LLMs are trained (next-token prediction) but the number of parameters in the model would be decreased. Knowledge distillation instead trains the smaller model to copy the outputs of the larger model.
The training process looks something like this:
Train a larger teacher model (or use an already trained model).
Initialize the student model.
Do a forward pass feeding an input to both the teacher and the student.
Compute loss between the output of the teacher and student.
Back propagate along the student only to adjust weights.
These steps continue until the student has completed training. This takes advantage of the capabilities of the large LLM to store knowledge to train the smaller model. Knowledge distillation has not only created more capable smaller models but it has also shown potential for that training to be significantly less resource intensive. The Gemma 2 report showcases this potential and expands upon the benefits of knowledge distillation..
Disclaimer: I’m not an expert on knowledge distillation, so if I have any information wrong please correct me in the comments.
If this article interests you, I write about the engineering behind AI each week. Subscribe to get each article in your inbox.
An Overview of the Gemma 2 Technical Report
Google trained Gemma 2 in many sizes both from scratch and using knowledge distillation to compare them. They trained:
From scratch: 27B, 9B, 7B, and 2.6B parameter models.
Distilled: 9B and 2.6B parameter models. The 9B model was a student to the 27B model and the 2.6B model was a student to the 7B model. These sizes were chosen to maintain a parameter ratio between both students and teachers for more accurate comparisons.
Google compared these models on benchmarks and found that distilled models performed better on benchmarks than their from-scratch counterparts.

They also found the distilled models to have consistently lower perplexity scores (this is a measure of a model’s uncertainty on new data).

Google also compared the distilled models to the previous iteration of Gemma models trained from scratch and found an up to 10% improvement in performance. I might be reading this section incorrectly, but comparing the newer distilled models to the previous generation of Gemma models trained from scratch means there are likely other training factors listed in the report that have contributed to this performance gain outside of just knowledge distillation. Regardless, results show better performance from distilled models.

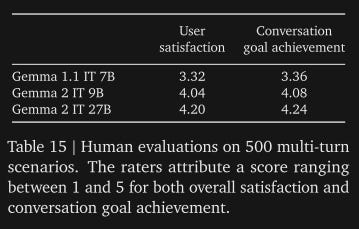
Google judged the Gemma 2 family on user satisfaction by having users rate an interaction with a model on a score from 1 to 5. They found the smaller 9B parameter model to reach a user satisfaction score 96% that of the 27B parameter model.
User satisfaction is a good metric to use here. While it isn’t all encompassing of model performance, having users rate LLM interactions is (in my opinion) a more accurate representation of how a model performs on the task being rated if the ratings are done fairly. Benchmarks are an excellent tool but many model creators have found ways to game them and because of this we’ve seen models with impressive benchmark scores that are entirely unremarkable in practice.
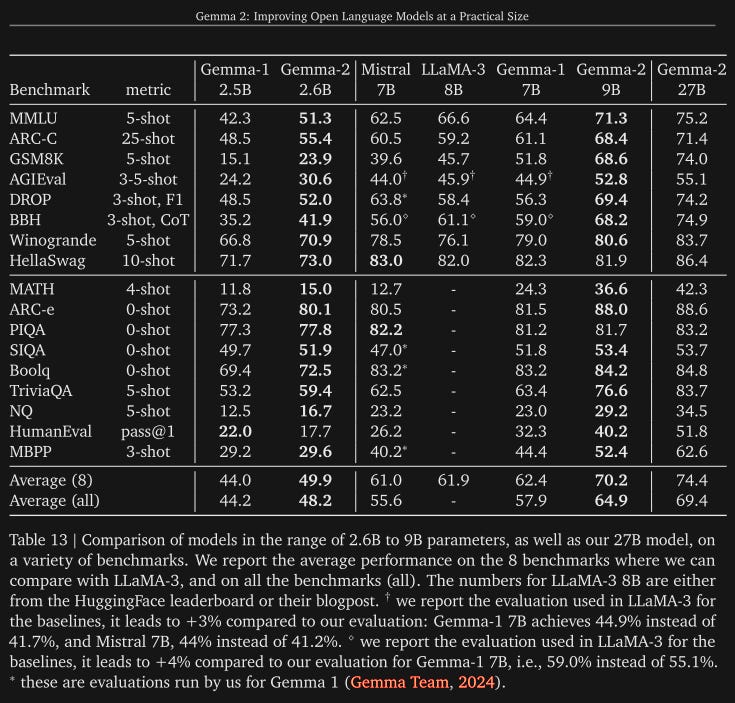
There’s other information in the report about the Gemma 2 family that doesn’t have to do with knowledge distillation. Most of it is regarding beating competition. I won’t cover it but if you want to check out the performance of the Gemma 2 family see the chart below.
The Benefits and Drawbacks of Knowledge Distillation
The benefits of knowledge distillation are numerous:
Smaller models with great performance. This means many things:
Less expensive serving and training. A ballpark estimate shows a potential 30-90% resource usage reduction with only a 3-10% model performance hit compared to the teacher model. In many applications, the small performance hit is unnoticeable but the resource reduction has a massive impact.
Faster inference. LLMs will run faster when answering user questions because the served models are smaller.
Accessible on more devices running locally which means greater accessibility and greater privacy for the user and more applications.
Reduced carbon footprint. Less compute time means less energy usage.
Improved model performance compared to from scratch training as seen in the Gemma 2 technical report.
The ability to further reduce size using other LLM size-reducing techniques such as quantization.
Can train multiple student models to take advantage of the knowledge extracted by a single teacher.
There are downside to knowledge distillation:
This might be common sense but you need a teacher model to train students. Training a teacher to train students can be expensive.
Large teacher models can eat into the efficiency gains of knowledge distillation. This is especially applicable for LLMs because state-of-the-art teacher models can be expensive to even run inference on. When training a student, the teacher must be running the forward pass alongside it. This means the efficiency gained via teacher-student training can largely depend on the architecture of the teacher model.
Training students on proprietary teacher models has legal ramifications. Teaching a smaller student model to mimic a proprietary model (such as GPT-4) makes the student only suitable for research applications. Thanks again to Cameron for pointing this out.
Other Examples of Knowledge Distillation
Here are some other popular examples of knowledge distillation:
DistilBERT (Hugging Face) from "DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter". It created a smaller, faster version of BERT that retained 97% of its language understanding capabilities while being 60% faster and 40% smaller.
TinyBERT (Huawei) from "TinyBERT: Distilling BERT for Natural Language Understanding". It compressed BERT models for mobile and edge devices while maintaining high performance for use in mobile applications and IoT devices. It achieved 96.8% the performance of its teacher while being 7.5x smaller and 9.4x faster on inference.
Knowledge Distillation in Recommendation Systems from "Ranking Distillation: Learning Compact Ranking Models With High Performance for Recommender System". It created more efficient recommendation models by training from a teacher model to improve the speed of recommendation systems.
Deep Neural Network Model Compression from "Model Compression via Distillation and Quantization". It reduced the computational requirements of deep learning models by using both quantization and knowledge distillation.
What Knowledge Distillation Means for You
Knowledge distillation efficiency gains can make AI much more accessible and affordable. Smaller models mean they can run on more devices and are less computationally demanding. This means the potential to bring state-of-the-art LLM performance to a user’s phone. Locally running LLMs on consumer devices means consumers pay less to run the model and their data stays private as it never leaves their device.
Another reason I find knowledge distillation so fascinating is it perfectly demonstrates the importance for software engineers to understand machine learning. One of the biggest benefits of using machine learning in software systems is the ability to change how a system works by changing data instead of code.
When a change needs to be made to a traditional software system, it requires engineers to change the system code to modify its performance. As any engineer knows, large-scale changes can be tedious and time consuming. Machine learning can make this easier. Once a model architecture is coded, the functionality of it can be changed by training it on different data as long as the new training data is available and the model architecture is capable of the new task. This means minimal (or no) code changes–only retraining.
Knowledge distillation utilizes this principle by taking the same architecture that can be used for next-token prediction on a smaller model and instead training it to mimic the outputs of its teacher. Machine learning systems can be extremely flexible and are programmed correctly.
If you’re interested in learning machine learning, I’ve put together the most streamlined road map to take you from prerequisites to advanced machine learning topics for free. You can also feel free to reach out to me on X with any questions. I also share ML information and important updates there.
Always be (machine) learning,
Logan
Resources
Here are the resources I read through as I prepared this:
Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality
Orca: Progressive Learning from Complex Explanation Traces of GPT-4
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
TinyBERT: Distilling BERT for Natural Language Understanding
Ranking Distillation: Learning Compact Ranking Models With High Performance for Recommender System
If you’re looking for even more resources here’s a very comprehensive repo containing many papers, video resources, and implementation examples of knowledge distillation.