


Alignment: Understanding the Multi-Billion Dollar Opportunity within Machine Learning
A glimpse into the biggest challenge in the world of AI, why it matters to you, and why it's worth so much

Alignment is one of the most important topics within modern machine learning (ML). Whether you’re a consumer of ML products, a person building them, or a company solving problems with them, alignment is something you should be aware of and understand well. Within AI, alignment dictates:
Privacy: Guaranteeing the responsible use of user data.
Security: Safeguarding users and systems from exploitation.
Research & Development: Improving model performance.
Product Excellence: Delivering optimal (and intended) user experiences.
To put it simply: alignment ensures AI systems achieve desired outcomes and align with human values, goals, and ethical principles. It means the outputs of ML systems not only align with the creator’s intentions, but also that these systems safe and reliable for users.
The stochastic nature and unpredictability of model outputs makes this a much more difficult task than it seems, but to fully utilize ML in a wide range of real-world applications, aligning AI to fit human use cases is an absolute must. Alignment is an excellent example of a complex ML problem that needs to be solved (as a machine learning engineer, I love this), meaning there is also a huge financial incentive to do so (as a father of 5, I also love this).
Let’s dig into what alignment is and why it matters to you.
Why Aligning Models is so Complex
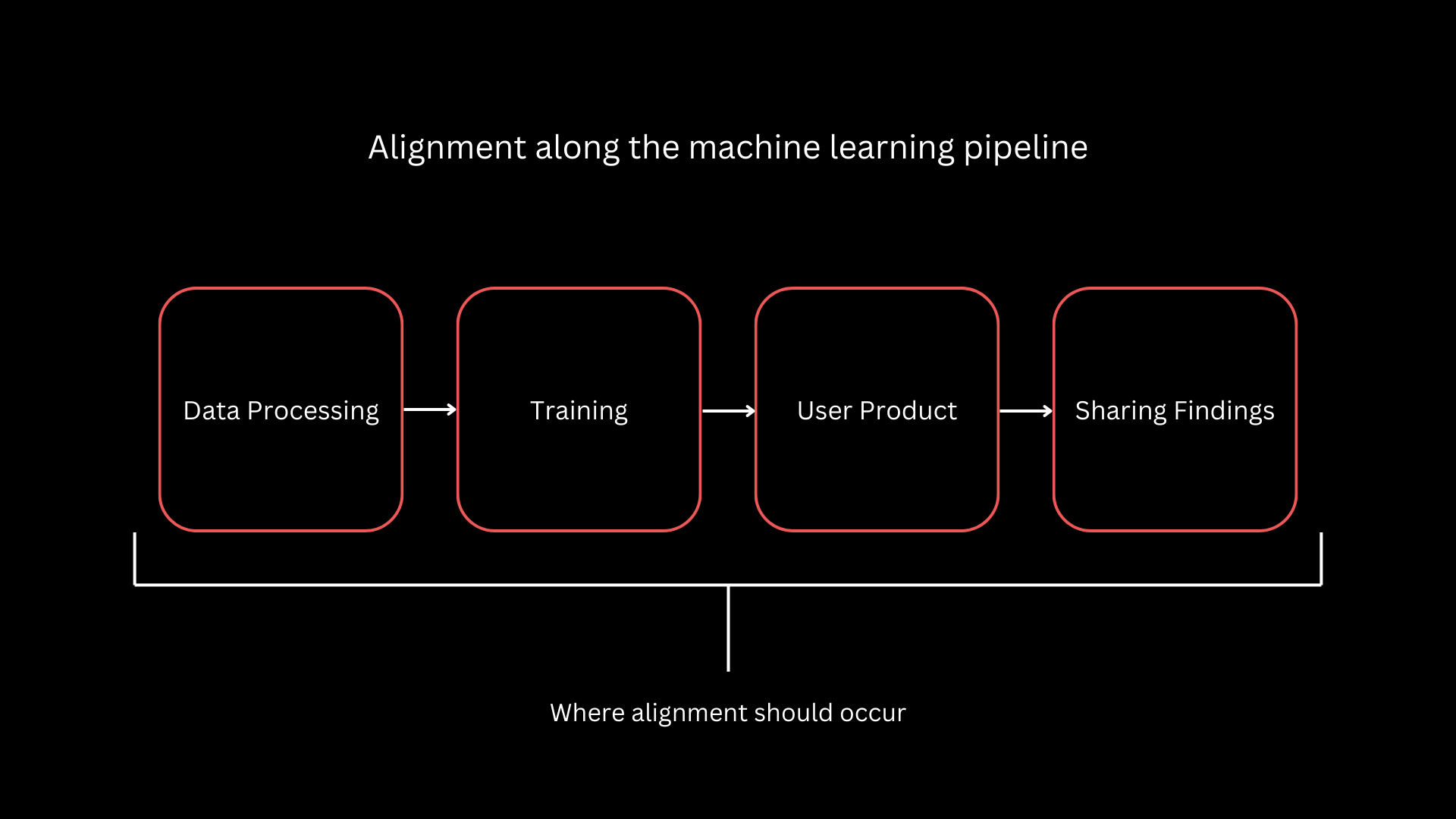
I’ve read many articles considering alignment to be a practice that occurs at the end of the training process during fine tuning of a model. In reality, alignment should occur throughout the entire machine learning pipeline. Many factors go into determining a model’s output, all of which need to be properly aligned.
All of the large players in the LLM space work to align their models, but none are able to get it done perfectly because it’s a subjective process done on an unpredictable algorithm. Alignment changes based on the desired output for an AI system, on the human values in consideration for using the AI, and how the creators of the AI determine is the best method of aligning the system with those two things.
As we discuss alignment more, remember the things that make alignment a huge, complex problem space:
It’ll continue changing. There is no one-size-fits-all approach. As human values and ML applications change, so will proper alignment methods.
Alignment needs to be considered throughout the entire machine learning training process. There are many factors that go into a model’s output and each have an impact on proper model alignment.
Why Consumers Should Care about Alignment
Alignment plays a central role in determining both the efficacy and safety of AI products. A significant proportion of ML models leverage user data and well-aligned models need to prioritize responsible data handling. This means user data is used solely for the benefit of the providing user and remains inaccessible to others. As a consumer, you should understand the alignment of the ML products you use to know if your data is being used maliciously.
The recent privacy concerns about ChatGPT sparked discussion regarding this on X. Initially, it wasn't explicitly understood that conversations had with ChatGPT would be used to further train GPT models (I’m sure this was in the terms of service somewhere). Many people were using ChatGPT for personal reasons and realized their personal conversations were being used to train GPT. This was especially concerning for companies trusting OpenAI with their user’s data as they used it with GPT-4. Luckily, data sent via the OpenAI API is never used for training purposes.
breaks down why a consumer’s data being used for training a model is a big deal for the consumer in his article Extract Training Data from ChatGPT. He writes about a paper from Google DeepMind showing that it's remarkably easy to extract training data from ChatGPT. This means anything these users have given to ChatGPT can potentially be output to any other ChatGPT user. Alignment is super important for consumers: properly aligned models protect user data.To be fair to OpenAI, ChatGPT isn’t the only mode capable of regurgitating memorized training data. ChatGPT is just by far the most widely used LLM, especially by non-technical consumers who wouldn’t understand how their data is being used.
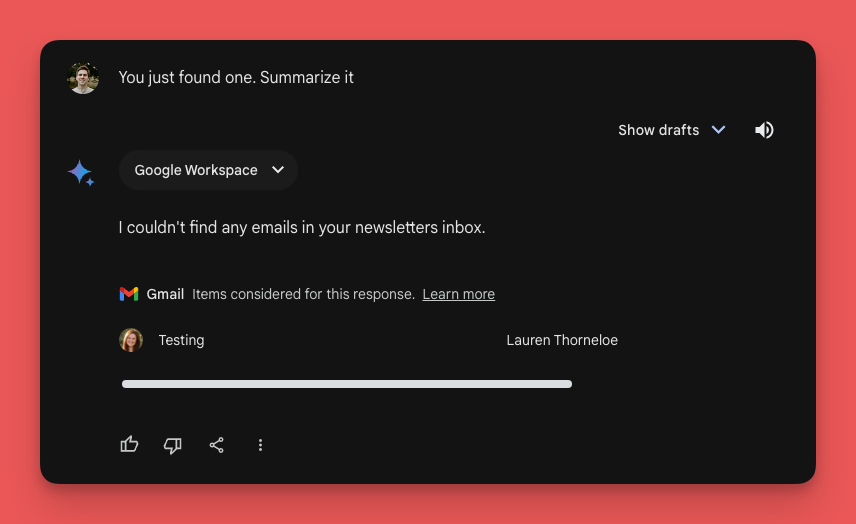
Alignment is also important for correct product behavior. I've experienced this recently as I’ve observed Gemini (when it was formerly Bard) erring on the side of excessive privacy protection to the point of hindering its own functionality. The main draw to Gemini for me is its ability to integrate with all my documents and emails stored in Google Drive. ChatGPT can’t do that. But apparently sometimes Bard can’t either.
In the screenshot above, you can see Bard telling me it is unable to access the emails in my newsletters inbox while showing me an email from my newsletters inbox. Just prior to this screenshot, Bard was pulling up those emails just fine and summarizing them for me. This apparent 'hard stop' for accessing user data might exist to prevent unintended data access, but it also hinders core product functionality. Properly aligned models would be able to prevent privacy issues and maintain product functionality.
Additionally, alignment is central to mitigating risks with AI generation. While arguably related to maintaining product functionality, hallucination and copyright infringement warrant separate attention given their novelty.
Hallucinations can be difficult to control and carry potentially severe consequences. I was using ChatGPT for meal planning for a while until one of my readers (thank you Sarah!) pointed out to me that it can recommend unsafe cooking practices. As an inexperienced chef, I wouldn’t have picked up on that on my own.

Midjourney and other image generation AI have been under fire recently regarding copyright issues. Interesting questions about copyright law, such as:
Is it acceptable for generative AI models to create an image of The Flash in response to a prompt of "create an image of a fast superhero"?
If so, can those images be used freely by the prompter or are they subject to copyright law?
I lack a deep understanding of copyright law, but I find these questions interesting because it isn’t something I would have foreseen. It is another challenge for proper model alignment to face.
Alignment's Importance for Companies and Professionals
Companies releasing AI products will need to ensure they function properly for consumers. Engineers working on ML within those companies will have to understand alignment, wherever their role is within the model lifecycle. This complex problem will require communication across teams within companies to solve it. As mentioned previously, alignment (likely) won’t have a “one and done” solution. As teams further develop and scale models, proper alignment will continue to be an issue.
While countless products leveraging ML offer value, organizations that excel at aligning them to user needs and values will hold a competitive edge. I think widespread usage of Perplexity as an LLM of choice for search illustrates this principle. Perplexity has grown rapidly into a dominant competitor (possibly the leader) in the search LLM space because it delivers on its core intent— it provides factual answers while minimizing hallucinations. Compared to larger, broader LLMs, I find Perplexity's output much better aligned for this use case.
Alignment is so important for companies that it’s actually created a wave of businesses that provide "Alignment-as-a-Service" dedicated to helping other companies solve alignment issues. A good example of this is ScaleAI. For further insights regarding Alignment-as-a-Service, I recommend
‘s article: Alignment-as-a-service: Scale AI vs. the new guys. It’s a very insightful look into the business of Alignment-as-a-Service and what it provides other companies.
Strategies for Aligning Models
Now that we know why alignment is important, how do we do it? Let's outline some methods used by major companies to align their models.
Data
The significance of data in training ML models cannot be overstated. With regard to alignment, Devansh had a simple, but 100% effective method of never sharing sensitive training data in his article I linked above: If you don't want your model to output something, don't include it in the training data.
This clearly isn’t always possible, but it’s good to keep in mind when considering how alignment affects the data processing phase of ML. Consider data as the starting point for alignment. Including diverse, comprehensive, and high-quality data influences both model performance and model alignment.
Training
The focus for alignment is often on techniques used during training (often fine-tuning) to instill human values into models. Prominent training approaches like this include:
Validating Alignment: Using techniques to detect misalignment and then purposefully training misaligned models to ensure those techniques are able to properly detect misalignment.
Reinforcement Learning from Human Feedback (RLHF): Iteratively aligning the model based on human evaluations of its outputs.
AI-assisted RLHF: Scaling the RLHF (can we even call it “with human feedback” at this point?) process using separate models tasked with predicting the type of human feedback expected for a given output.
User Experience (UX)
Alignment can also occur using good ol’ fashioned software engineering at the level of the user experience. Consider the fact that LLMs need to be given context of their interactions. For example, telling ChatGPT they are a helpful chatbot in the prompt sent to the LLM. This is something I’ve done a lot of recently when building a summarizing tool using LLMs. I always have to let it know its a summarizer and what I expect from its summaries. These are both examples of aligning model output at the user experience.
Sharing Findings
Possibly the least emphasized, yet potentially most vital piece of solving the alignment problem lies in sharing findings about alignment techniques. Complex problems generally require many minds so solve. I think it’s especially important to converse with experts outside of the realm of AI to determine novel solutions to alignment issues, as these solutions may differ based on the field in which AI is being applied.
I think the importance (and impact) of proper model alignment can’t be overstated. It makes me excited to think about the problem areas we can solve related to it. Let me know what you think of my thoughts on alignment. If you disagree or want to make a correction, leave a comment below.
Also consider following me on X, I share a lot more information about AI and software engineering there.
Paid subs will begin getting articles about updates in the world of AI and what they mean for you. My goal is to make these the only source of info you need to stay up-to-date on the world of AI. If you're interested in this, become a paid member for 30% off forever:
Hey Logan,
Thanks for the mention. I forgot to get back to your earlier comment, so I thought I'd clarify here. The principle of don't give your model capabilities you don't want it to have goes beyond just the data.
For eg. teams are now looking for a way to remove hallucinations, have GPT do precise computations, and generate charts without any error. My supposition is that the tool doesn't do any of the things well. Instead of training it with a lot more resources, look at alternative techniques (use a reader model on specific contexts instead of entire documents, pass additions along to a computing function, and call matplotlib). Where Precision is a must- consider regular expressions for processing, rule engines for decision making. Instead of trying to take a tool, and mold it to fit the problem statement- define your needs first. Pick the tool by your need. That's generally what I mean by good design