


Discussions around OpenAI's o1, Superhuman AI, When AI Should Be An App, and More
Discussions from the past week: 09/16/2024

Here’s this week’s notable discussions that took place in the world of AI. I’m splitting the reading list into a separate article that will be sent out tomorrow. Top highlights are first and more in depth. Other important discussions and happenings are afterword. I’m trying out a new format, so let me know what you think! Link to last week’s updates/discussion points:

If you’re new to Society’s Backend, welcome! I write each week about important discussions in the world of AI, share my reading list, and explain important AI topics from an engineering perspective. Subscribe to get these articles directly in your inbox.
Enjoy! Don’t forget to leave a comment to let me know what you think.
Top Highlights
OpenAI o1
OpenAI release a new family of models called o1. They’ve released both o1 and o1-mini. You can check out the system card here. They claim these models think before they respond and are the first models that can actually reason. I was a bit disappointed that they didn’t release enough information about the models to really dig into this, but luckily the AI community has there ways and there’s been a ton of discussion about what “reasoning” means in this context and whether or not it’s an accurate claim.
Essentially, how o1 works it gets a prompt and goes through a chain-of-thought that breaks down the prompt into smaller chunks so it can work through each. This creates longer response that are more “thought out” and safer. The general consensus is these models work differently from the LLMs we’re used to with some claiming a new paradigm of AI. Prompting also appears to work differently because the model breaks down the prompt itself meaning traditional prompting methods won’t affect results the way we’re used to.
I think the best way to understand o1 and what it means is to take in a bunch of different perspectives from AI experts and those testing the model. Some of my favorites are about what o1 means for inference-time scaling of models, testing o1 on ARC-AGI where it showed disappointing results, and a comment about what o1’s reasoning means. It’s also worth reading Nathan Lambert’s article on reverse engineering OpenAI’s o1.
Reflection 70B Follow up
A quick follow up on last week’s Reflection 70B release being possibly fraudulent. I wanted to share some threads that provide some much-needed context:
Sebastian Raschka turned this into a learning moment to teach others about reflection-tuning.
A thread from the developer who sent the benchmark scores and why the mishap occurred.
A post from Hyperbolic Labs who hosted the model and their dealings with the creators of it. There’s quite a bit in this that makes me question the entire saga.
And a good post showing the only winners from fraudulent or mistaken claims are AI influencers who blow them up for clout. It’s an unfortunate reality the AI community has to deal with. If you want an article that details the saga, check out this article from Artificial Ignorance.
AI’s Biggest Problem is Communication
I created a post about how the biggest problem right now with AI is the inability to communicate how its beneficial to the target audience. For example, Apple’s demo showed someone taking a picture of someone else’s dog and using visual intelligence to figure out the breed. This was the example they decided to use to show consumers how they can use visual intelligence.
There’s a very clear problem here: no one would ever do this. No one would ask a stranger “Can I take picture of your dog?” Instead, they would just ask “What breed is your dog?” Sure, visual intelligence can be used here, but it’s not particularly useful. This isn’t just an Apple issue—most of the demoes I see (especially around consumer use cases) are pretty bad.
I don’t think anyone doubts the usefulness of AI, but I think AI companies are doing a poor job of helping people understand how they can use it. Let me know what you think about this. I’m very curious if you think the communication here is poor or if we truly haven’t found great use cases yet.
AI as Super-human Predictor
“Our bot performs better than experienced human forecasters and performs roughly the same as (and sometimes even better than) crowds of experienced forecasters; since crowds are for the most part superhuman, so is FiveThirtyNine.”
The Center for AI Safety released a demo of an AI that can predict the future at a superhuman level. This is essentially an AI that makes predictions with an accuracy on-par with a group of experienced human forecasters. The bot works by asking it a question about the future (i.e. Will Trump win the 2024 presidential election?) and it’ll give a prediction as an answer.
This immediately made me pause. LLMs are by definition prediction machines, but I couldn’t wrap my head around how we can make the definitive conclusion that the AI predicts at a superhuman level when its trained on predictions at the human level. This post very quickly got community noted for not being able to justify the claim and another X user used the model on a separate dataset where it showed much worse performance. Their thread including a list of issues they found with the model can be found here.
Links to the X announcement (including the system prompt) and technical paper.
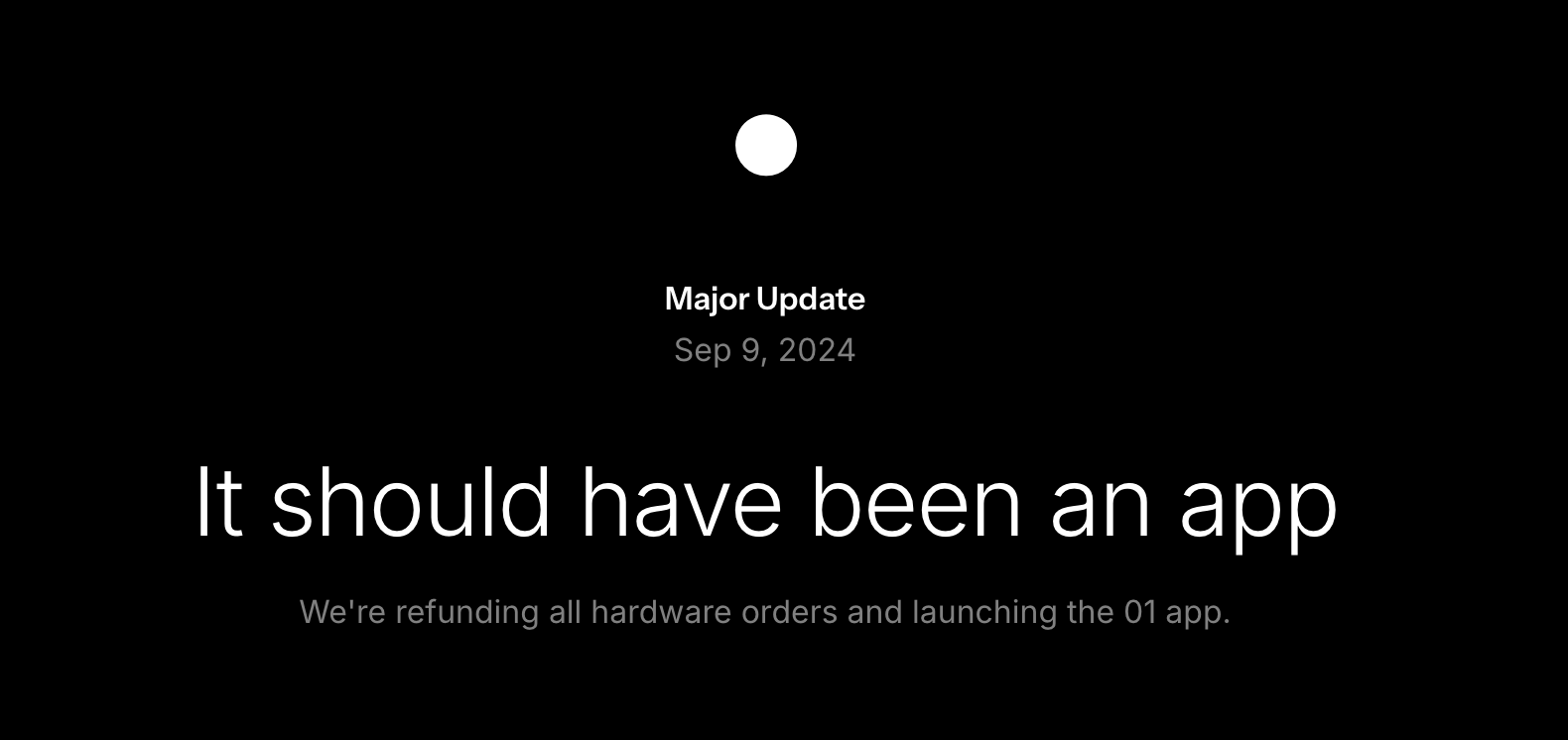
It should have been an app
“Compared to the engineering maturity of modern smartphones, we realized that the 01 Light’s hardware didn't offer enough value to justify manufacturing it.”
The O1 light is being discontinued, everyone is being refunded, and the Open Interpreter is being released as an app. A little background: the O1 Light was going to be a small gadget to let people interface with their computer via voice utilizing LLMs. It was cool, but the company realized everything could be done via an app—so they canceled it.
I’m including this because this is the way things like should be handled. As someone who builds technology centered around AI, there should have been a point in the development process of all of these products where they realized custom hardware wasn’t needed. Instead of using AI hype to sell products at the detriment of consumers (like some companies have), Open Interpreter made the right decision to discontinue building a separate hardware device. Not only that but they refunded everyone, launched a free app, open-sourced all their manufacturing materials, and still made an option of a cheap standalone device for those who want it.
The world of AI is ripe with opportunity to do the wrong thing and Open Interpreter did the right things. Read the X thread or blog post here to get all the details and the reasoning behind the decision.
Other Highlights
HuggingFace released FineVideo, a dataset for training video generation models released under the Creative Commons license.
Google’s NotebookLM allows user to generate a conversational podcast from their notes.
Mistral releases Pixtral, its first multimodal model. I tried to include the official press release as the link here but I found it interesting that it doesn’t seem to be listed anywhere in their news releases.
Deepsilicon is a startup developing software and hardware to train and run ternary transformers. I don’t know much about this so I’ll have to do more research, but initial claims are the ability to run neural networks ~20x faster with 1/5 the RAM.
ChaiDiscover releases Chai-1: a foundation model for molecular structure prediction. This came right after my post last week defending a ridiculous claim about Google DeepMind’s AlphaProteo.
The Harris platform is out. However you align politically, this is something to keep tabs on. Regulation in the US will have a big impact on AI.
Perplexity releases a discover feed. As a curious person, I think this is awesome. There are other companies with similar offerings but I’ve found all to fall short. It’s good to have another competitor.
Apple launches the iPhone 16 with Apple intelligence, including visual intelligence. It’s always good to have capable AI in the hands of more consumers.
Replit released an AI agent that can code and deploy applications for you. Initial testing has shown great promise in its abilities to function to democratize software development.
A good take from Lex Fridman about whether or not AI will replace programmers.
Someone conjured up a $10 million AI music scam. This really highlights how AI fundamentally changes the way things work and the thoughtfulness that needs to go into creating it.
Job Skill Updates
I’ve added a section on job skills to the ML road map. I’ll keep this section updated with the rest of the map and I’ll continue to add resources to help you learn these skills.
My first impression is I’m surprised at how many AI-related jobs focus heavily on standard software engineering skills first and then AI skills later. Languages like Java, C++, and Rust are emphasized in a lot of listing. It makes me wonder if employers see ML skills as easier to teach workers on the job than software engineering skills. It’s also possible there are a lot of SWE-focused ML jobs than pure ML researcher positions that are skewing these results.
I’ll be sending out my AI reading list tomorrow. Paid subscribers will get access to the entire list of all articles, papers, and videos worth looking into. Thanks for your support! If you’re interested in getting the full reading list of supporting Society’s Backend, you can subscribe for just $1/mo.